java集合框架
集合接口与实现分离
与现代的数据结构类库的常见做法一样,java集合类库也将接口与实现分离。下面用我们熟悉的数据结构——队列来说明是如何分离的。
队列接口指出可以在队列的尾部添加元素,在队列的头部删除元素,并且可以查找队列中元素的个数。当需要收集对象,并按照“先进先出”方式检索对象时就应该使用队列。
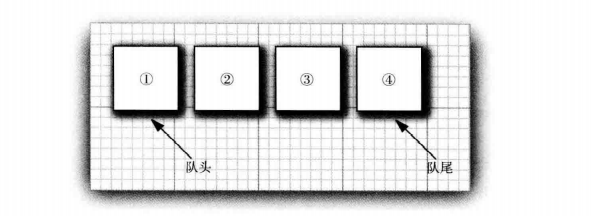
队列接口的最简形式可能类似下面这样:
1 | public interface Queue<E> |
这个接口并没有说明队列是如何实现的。队列通常有两种实现方式:一种是使用循环数组;另一种是使用链表。
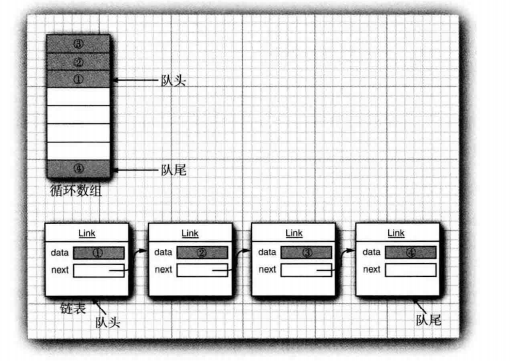
每一个实现都可以用一个实现了Queue接口的类表示。
1 | public class CircularArrayQueue<E> implements Queue<E> |
当在程序中使用队列时,一旦已经构造了集合,就不需要知道究竟使用了哪种实现。因此,只有在构造集合对象时,才会使用具体的类。可以使用接口类型存放集合引用。
1 | Queue<Customer> expresslane = new CircularArrayQueue<>(100); |
利用这种方法,一旦改变了想法,就可以很轻松地使用另外一种不同的实现。只需要对程序的一个地方1做出修改,即调用构造器的地方。如果觉得LinkedListQueue是个更好的选择,就将代码修改为:
1 | Queue1<Customer> expressLane =new LinkedListQueue<>(); |
为什么选择这种实现,而不选择那种实现呢?接口本身并不能说明哪种实现的效率究竟如何。循环数组要比链表更高效,因此多数人优先选择循环数组。不过,通常来讲,这样做也需要付出一定代价。
循环数组是一个有界集合,即容量有限。如果程序中要收集的对象数量没有上限,就最好使用链表来实现。
迭代器
Iterator接口包含4个方法:
1 | public interface Iterator<E> |
通过反复调用next方法,可以逐个访问集合中的每个元素。但是,如果到达了集合的末尾,next方法将抛出一个NoSuchElementException。因此,需要在调用next之前调用hasNext方法。如果迭代器对象还有多个可以访问的元素,这个方法就返回true。如果想要查看集合中的所有元素,就请求一个迭代器,党hasNext返回true时就反复地调用next方法。例如:
1 | Collection<String> c=...; |
用”for each”循坏可以更加简练地表示同样的循环操作:
1 | for(String element : c) |
编译器简单地将”for each”循环转换为带有迭代器的循坏。
“for each”循环可以处理任何实现了Iterable接口的对象,这个接口只包含一个抽象方法:
1 | public interface Iterable<E> |
访问元素的顺序取决于集合类型。如果迭代处理一个ArrayList,迭代器将从索引0开始,每迭代一次,索引值加1.不过,如果访问HashSet中的元素,会按照一种基本上随机的顺序获得元素。虽然可以确保在迭代过程中能够遍历到集合中的所有元素,但是无法预知访问各元素的顺序。这通常并不是什么问题,因为对于计算总和或统计匹配之类的计算,顺序并不重要。
Java集合类库中的迭代器与其他类库中的迭代器在概念上有着重要的区别。在传统的集合类库中,例如,C++的标准模版库,迭代器是根据数组索引建模的。如果给定这样一个迭代器,就可以查看指定位置上的元素,就像知道数组索引i就可以查看数组元素a[i]一样。不需要查找元素,就可以将迭代器向前移动一个位置。这与不需要执行查找操作就可以通过i++将数组索引向前移动一样。但是,Java迭代器并不是这样操作的。查找操作与位置变更是紧密相连的。查找一个元素的唯一方法是调用next,而在执行查找操作的同时,迭代器的位置随之向前移动。
因此,应该将Java迭代器认为是位于两个元素之间。当调用next时,迭代器就越过下一个元素,并返回刚刚越过的那个元素的引用。
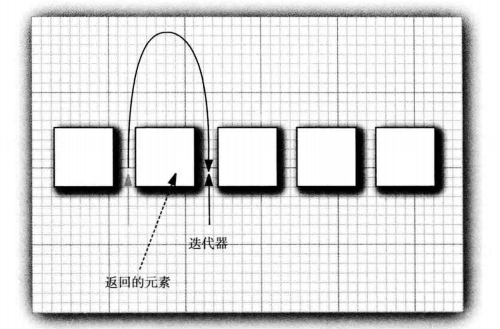
Iterator接口的remove方法将会删除上次调用next方法时返回的元素。在大多数情况下,这是有道理的,在决定删除某个元素之前应该先看一下这个元素。不过,如果想要删除指定位置上的元素,仍然需要越过这个元素:
1 | Iterator<String> it =c.iterator(); |
更重要的是,next方法和remove方法调用之间存在依赖性。如果调用remove之前没有调用next,将是不合法的。如果这样做,将会抛出一个IllegalStateException异常。
如果想删掉两个相邻的元素,不能直接这样调用:
1 | it.remove(); |
实际上,必须先调用next越过要删除的元素。
1 | it.remove(); |
具体集合
链表
链表是一个有序集合。
1 | ListIterator<E> ListIterator() |
返回一个列表迭代器,用来访问列表中的元素。
1 | ListIterator<E> listIterator(int index) |
返回一个列表迭代器,用来访问列表中的元素,第一次调用这个迭代器的next会返回给定索引的元素。
1 | void add(int i,E element) |
在给定位置添加一个元素。
1 | void addAll(int i,Collection<?extends E>elements) |
将一个集合中的所有元素添加到给定位置。
1 | E remove(int i) |
删除给定位置的元素。
1 | E get(int i) |
获取给定位置的元素。
1 | E set(int i,E element) |
用一个新元素替换给定位置的元素,并返回原来那个元素。
1 | int indexOf(Object element) |
返回与指定元素相等的元素在列表中第一次出现的位置,如果没有这样的元素就返回-1.
1 | int lastIndexOf(Object element) |
返回与指定元素相等的元素在列表中最后一次出现的位置,如果没有这样的元素将返回-1.
1 | void add(E newElement) |
在当前位置添加一个元素。
1 | void set(E newElement) |
用新元素替换next或previous访问的上一个元素。如果在上一个next或previous调用之后列表结构被修改了,将抛出一个IllegalStateException异常。
1 | boolean hasPrevious() |
当反向迭代列表时,如果还有可以访问的元素,返回true。
1 | E previous() |
返回前一个对象。如果已经到达了列表的头部,就抛出一个NoSuchElementException异常。
1 | int nextIndex() |
返回下一次调用next方法时将返回的元素的索引。
1 | int previousIndex() |
返回下一次调用previous方法时将返回的元素的索引。
1 | LinkedList() |
构造一个空链表。
1 | LinkedList(Collection<?extends E>elements) |
构造一个链表,并将集合中所有的元素添加到这个链表中。
1 | void addFirst(E element) |
将某个元素添加到列表的头部或尾部。
1 | E getFirst() |
返回列表头部或尾部的元素。
1 | E removeFirst() |
删除并返回列表头部或尾部的元素。
散列表
1 | HashSet() |
构造一个空散列集。
1 | HashSet(Collection<?extends E>elements) |
构造一个散列集,并将集合中所有元素添加到这个散列集中。
1 | HashSet(int initialCapacity) |
构造一个空的具有指定容量的散列集。
1 | HashSet(int initialCapacity,float loadFactor) |
构造一个有指定容量和装填因子的空散列集。
1 | int hashCode() |
返回这个对象的散列码。
树集
1 | TreeSet() |
1 | TreeSet(Comparator<?super E> compartor) |
构造一个空数集。
1 | TreeSet(Collection<?extends E>elements) |
构造一个树集,并增加一个集合或有序集中的所有元素。
映射
1 | V get(Object key) |
获取与键关联的值;返回与键关联的对象,或者映射中如果没有这个对象,就返回NULL。
1 | V put(K key,V value) |
将关联的一对键和值放到映射中。
1 | void putAll(Map<?extends K,?extends V>entries) |
将给定映射中的所有映射条目添加到这个映射中。
1 | boolean containsKey(Object key) |
如果在映射中已经有这个键,返回true。
1 | boolean containsValue(Object value) |
如果映射中已经有这个值,返回true。