绪论
奥卡姆剃刀:若有多个假设与观察一致,则选择最简单的那个。
NFL定理(No Free Lunch Theorem):所有学习算法期望性能相同。
Independent and identically distributed,独立同分布,IID
模型评估与选择
经验误差与过拟合
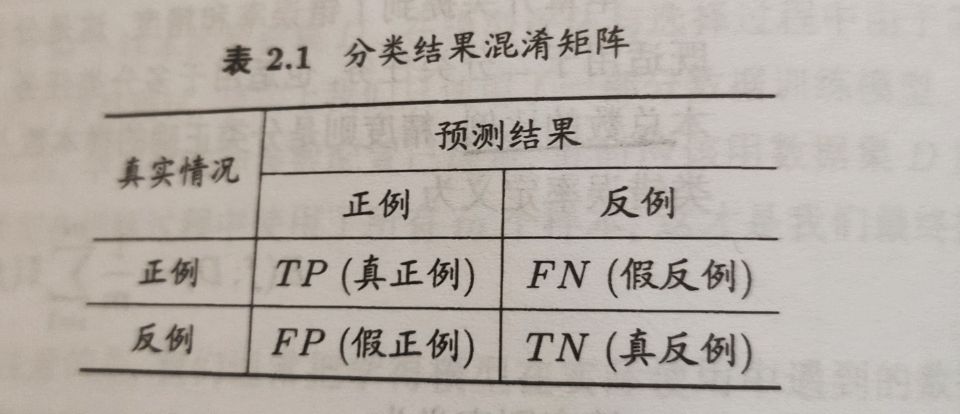
若在m个样本中有a个样本分类错误,则称错误率为E=a/m;
精度=1-错误率;
学习器在训练集上的误差称为训练误差或经验误差,在新样本的误差称为泛化误差。
过拟合:把训练样本自身的一些特点当成了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。
欠拟合:训练样本的一般性质尚未学好。
评估方法
留出法
直接将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试集。
分层采样:保留类别比例的采样方式。
交叉验证法
先将数据集D划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,从而进行k次训练和测试,最终返回k个测试的均值。通常把交叉验证法称为k折交叉验证法。
当k=m时,得到交叉验证法的特例:留一法(Leave-One-Out,简称LOC)。留一法评估结果往往比较准确,但计算开销较大。
自助法
以自主采样为基础,给定包含m个样本的数据集,每次随机从中挑选一个并放回,重复执行m次,则得到一个包含m个样本的数据集$D’$,样本在m次采样中始终不被取得的概率取极限为0.368.这样的测试结果,也称为包外估计。
自助法在数据集较小,难以有效划分训练/测试集时很有用。但是自助法产生的数据集会改变初始数据集分布,这会引入估计偏差,因此,在数据量足够时,留出法和交叉验证法更加常用。
性能度量
在预测任务中,给定样例集$D={(x_1,y_1),(x_2,y_2),…,(x_m,y_m)}$,其中$y_i$是示例$x_i$的真实标记。
回归任务最常用的性能度量是均方误差。
下面是一些常用的性能度量。
错误率与精度
对样本集D,分类错误率定义为
精度定义为
查准率、查全率与F1
查准率P:$P=\frac{TP}{TP+FP}$
查全率R:$R=\frac{TP}{TP+FN}$
查准率与查全率为一对矛盾的度量。通常只有在一些简单任务中,才可能使查准率与查全率都很高。
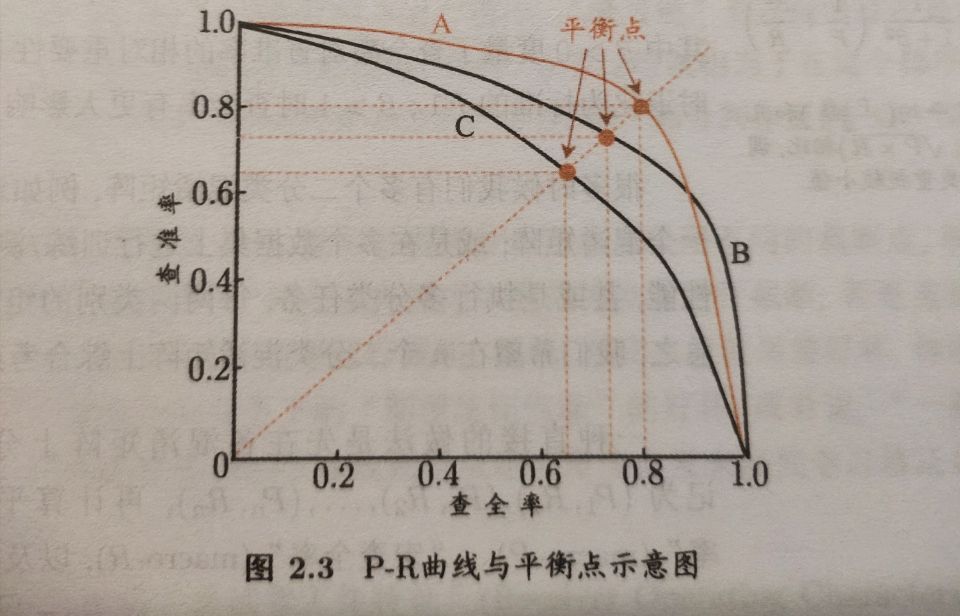
若一个学习器的PR曲线完全被另一个学习器的曲线包住,则可断言,后者的性能优于前者。
平衡点(Break-Even Point,简称BEP)为查准率与查全率相等时的取值。
但BEP度量还是简单一点,更为常用的是F1度量:
F1度量的一般形式-$F_\beta$
$\beta$>1查全率有更大影响。

ROC与AOC
ROC曲线的纵轴是真正例率(True Positive Rate,TPR),横轴是假正例率(False Positive Rate,FPR)
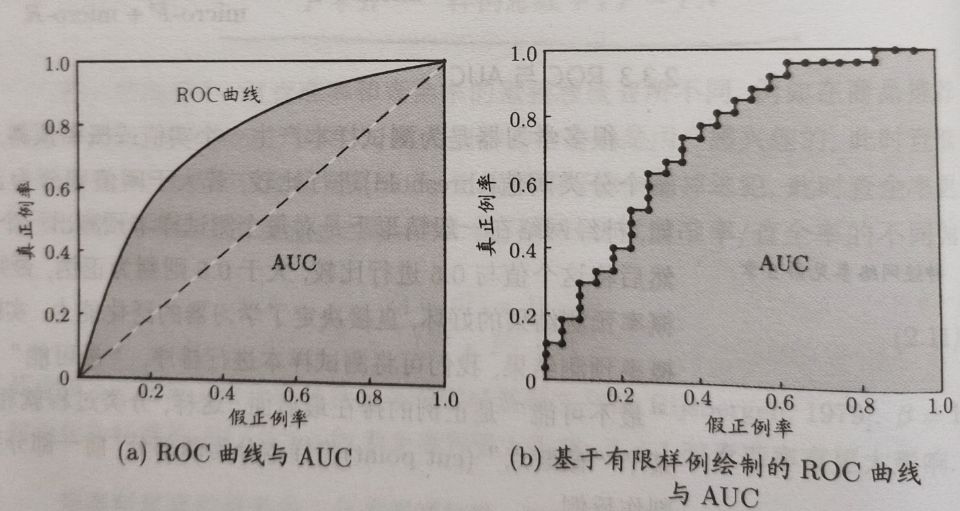
若一个学习器的ROC曲线被另一个学习器的曲线完全“包住”,则可断言后者性能优于前者。但是当有交叉时,一般难以判断,此时较为合理的依据是比较ROC曲线下的面积,即AUC.(Area Under ROC Curve)
$l_{rank}$定义为
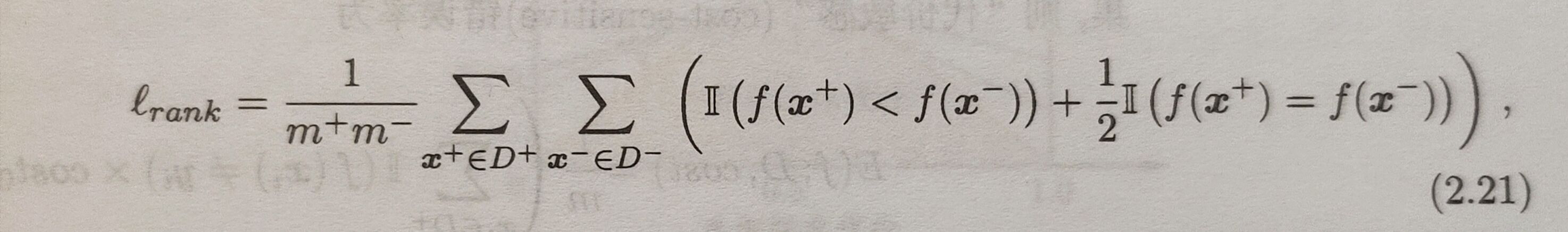
AUC=1-$l_{rank}$
以下为对$l_{rank}$的通俗解释:
假设我们在做一个手写数字识别,识别样本数字是否为5,输入12个数字,经过算法得出每个数字的打分从小到大如下(分越高表示算法认为这个数字越接近5,用A表示正例,B表示反例):B1,B2,B3,B4,A1,B5,A2,A3,B6,A4,A5,A6
对于第一个正例A1,有两个反例比他大,则为2,对于第二三个正例,有一个,其余没有,则分子为2+1+1+0+0+0=4,分母为正例数,反例数=6*6=36,则此时$l_{rank}$为4/36=1/9
代价敏感错误率与代价曲线
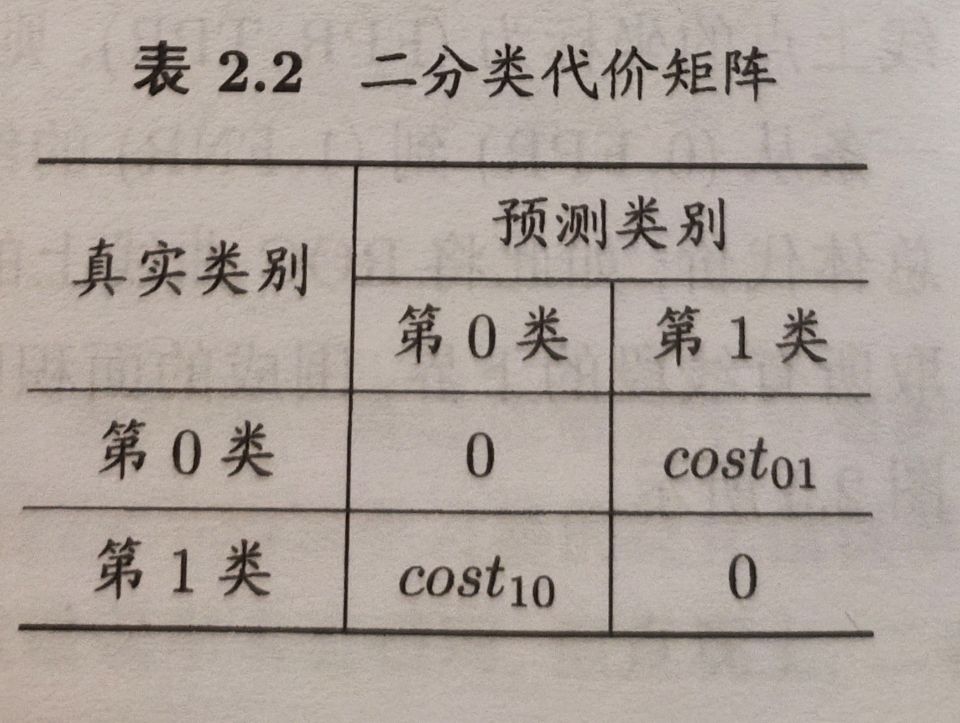
代价敏感错误率为
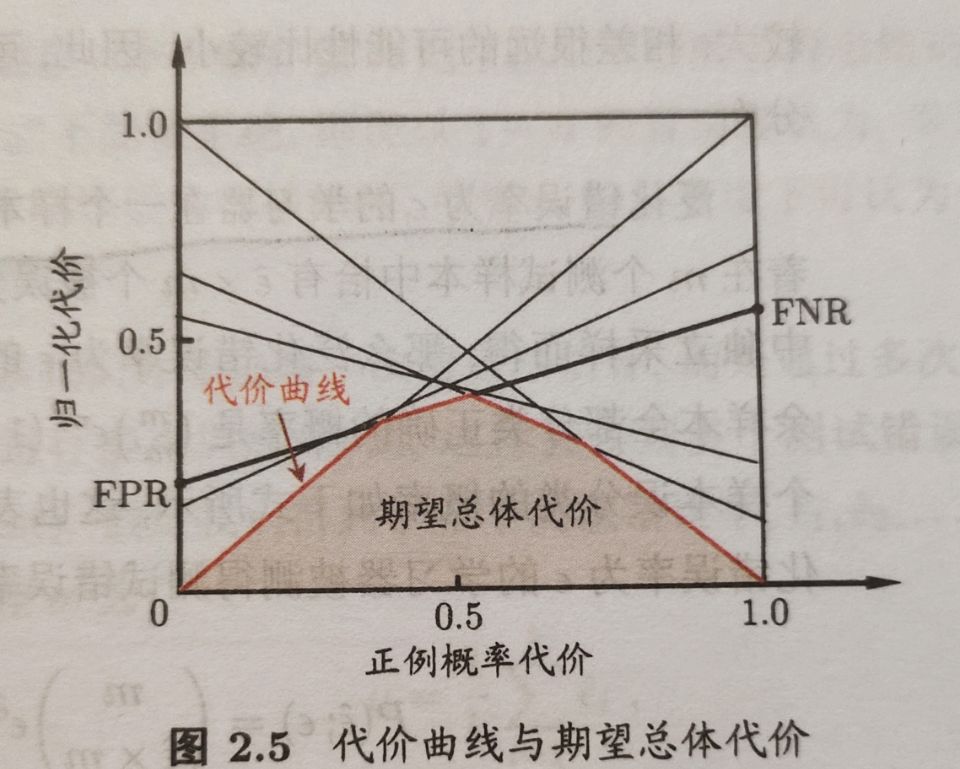
在非均等代价下,ROC曲线不能直接反映出学习器的期望总体代价,而代价曲线则可达到该目的。
代价曲线图的横轴是取值为[0,1]的正概率代价
代价曲线图的横轴是取值为[0,1]的正例概率代价
其中p是样例为正例的概率;纵轴是取值为[0,1]的归一化代价
代价曲线绘制很简单:ROC曲线上每一点对应了代价平面上的一条线段,设ROC曲线上点的坐标为(FPR,TPR),则可计算出FNR,然后在代价平面上绘制一条从(0,FPR)到(1,FNR)的线段,线段下的面积表示了该条件下的期望总体代价。
比较检验
本节默认以错误率为性能度量,用$\epsilon$表示
假设检验
泛化错误率为$\epsilon$的学习器在一个样本上犯错的概率是$\epsilon$;测试错误率$\hat{\epsilon } $意味着在m个测试样本中恰好有$\hat{\epsilon } $*m个被误分类。
我们可使用“二项检验”来对“$\epsilon$<=$\hat{\epsilon}_0$”这样的假设进行检验。
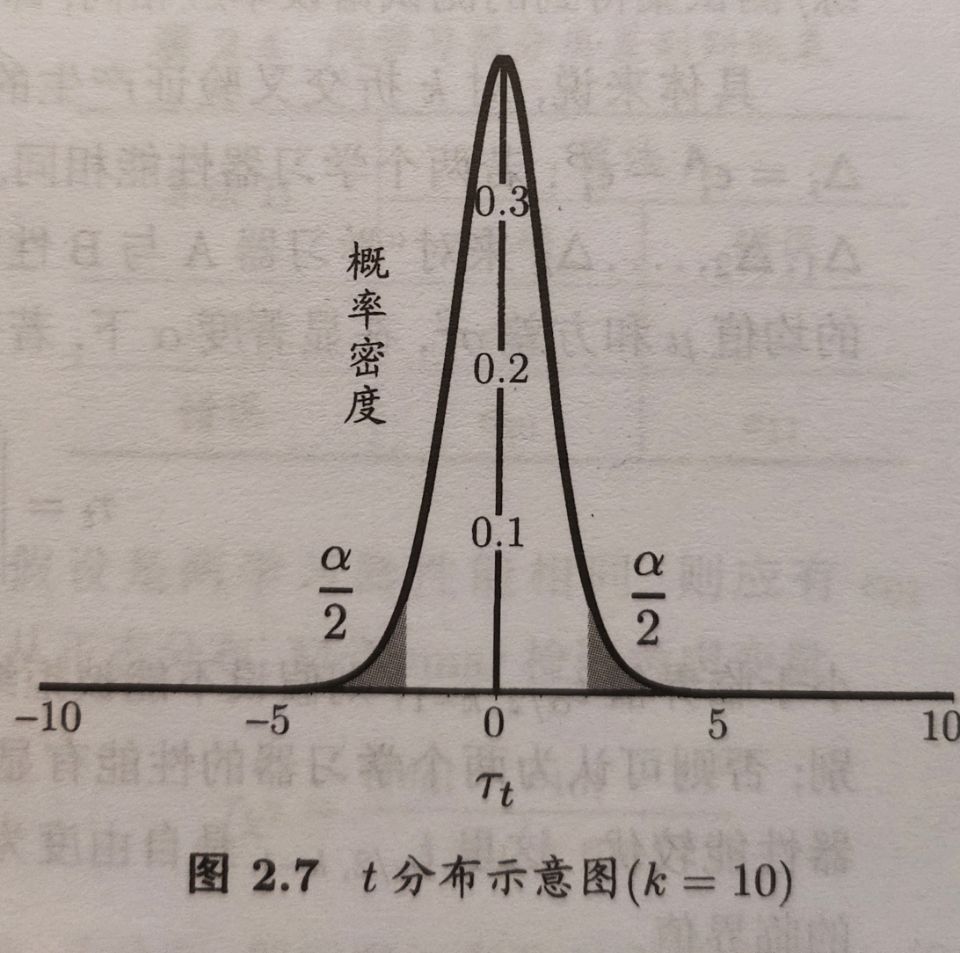
在很多时候我们并不是做一次留出法估计,而是通过多次重复留出法或是交叉验证法等进行多次训练和测试,这样会得到多个测试错误率,此时可用”t-检验”。平均测试错误率$\mu$和方差$\sigma^2$为
考虑到k个测试错误率可看作泛化错误率$\epsilon_0$的独立采样,则变量
服从自由度为k-1的t分布。
交叉验证t检验
对于两个学习器A和B,若我们使用k折交叉验证法得到的错误测试率分别为$\epsilon^A_1$…和$\epsilon_1^B$…,则可使用k折交叉验证”成对t检验”来进行比较检验。可根据差值来对学习器A与B性能相同这个假设做t检验,计算出插值的均值$\mu$和方差$\sigma^2$,在显著度$\alpha$下,若变量
小于临界值,则假设不能被拒绝。
McNemar检验
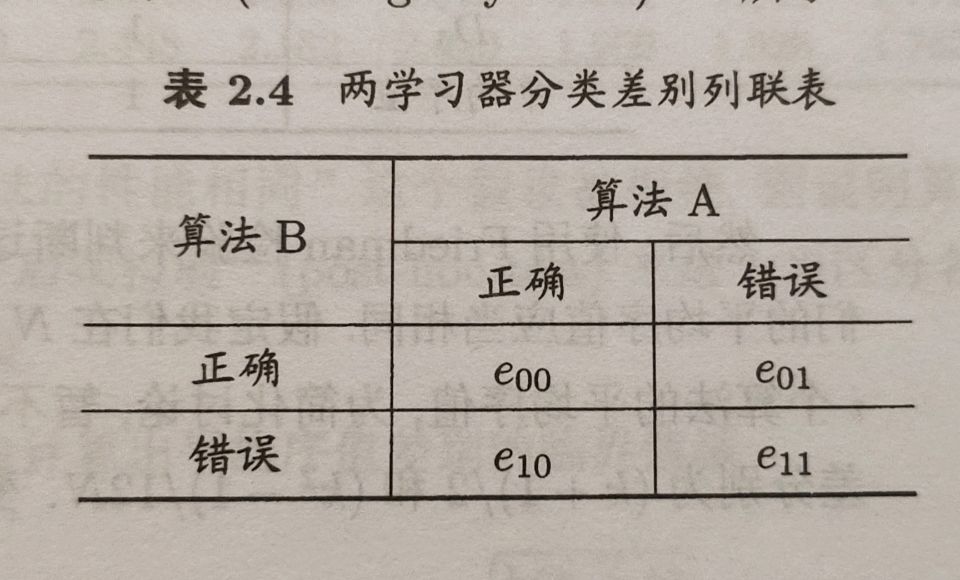
若我们做的假设是两学习器性能相同,则应有$e{01}=e{10}$,那么变量$|e{01}-e{10}|$应当服从正态分布。McNemar检验考虑变量
服从自由度为1的$\chi^2$分布
Friedman检验与Nemenyi后续检验
之前介绍的都是在一个数据集上比较两个算法的性能,而在很多时候,我们会在一组数据集上比较多个算法。此时可以使用基于算法排序的Friedman检验。
当所有算法性能相同这个假设被拒绝,则说明算法的性能显著不同,这时需要后续检验来区分,常用的有Nemenyi后续检验。
偏差与方差
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
噪声则表达在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度,
泛化误差可分解为偏差、方差与噪声之和。
线性模型
基本形式
f(x)=w1x1+w2x2+…+wdxd+b
一般用向量形式写成
线性回归
线性回归试图学得
多元线性回归
对数线性回归
广义线性模型
对数几率回归
对数几率函数,“Sigmod函数”,将Z值转换为1个接近0或1的y值,并且其输出在z=0附近变化很陡。
带入得
将上述式子变换得
注:极大似然估计,梯度下降法,牛顿法,请参考实验。
线性判别分析
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的线性学习方法。
LDA的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
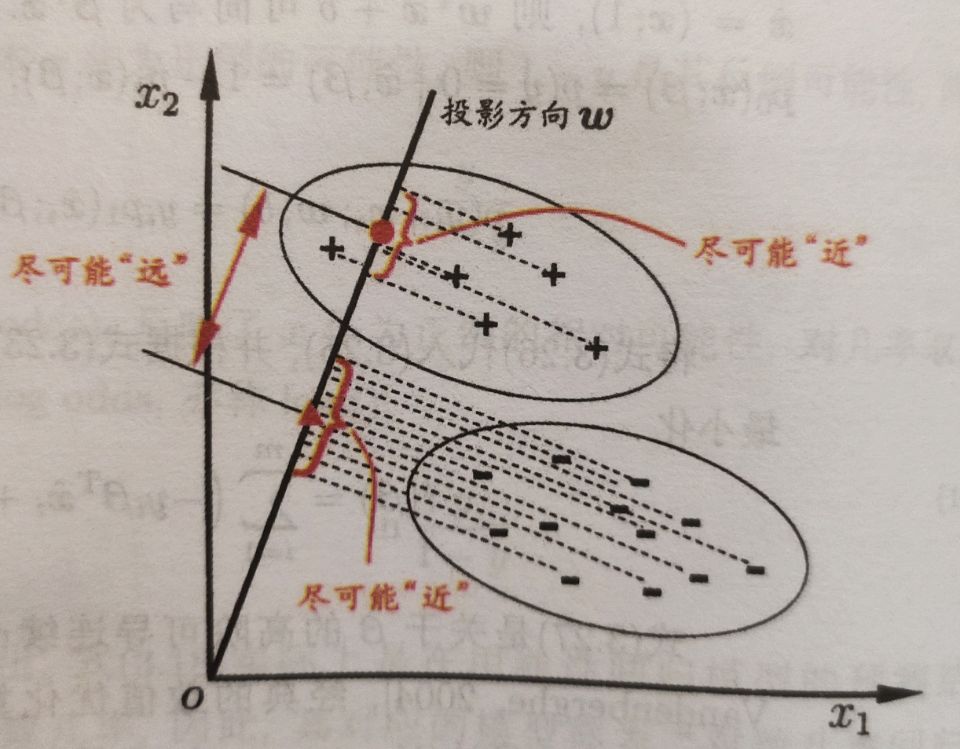


定义类内散度矩阵
类间散度矩阵$S_b=(\mu_0-\mu_1)(\mu_0-\mu_1)^T$
则有最大化目标
这就是LDA想要最大化的目标,即$S_b与S_w$的“广义瑞利商”。
上述式子只与$w$的方向有关,与长度无关,故不是一般性,令$w^TS_ww=1$,根据拉格朗日乘子法,等价于
注意到$S_bw$的方向恒为$\mu_0-\mu_1$
则令$S_bw=\lambda(\mu_0-\mu_1)$
代入得$w=S^{-1}_w(\mu_0-\mu_1)$
考虑到数值解的稳定性,在实践中通常是对$S_w$进行奇异值分解,即$S_w=U\Sigma V^T$
值得一提的是,LDA可从贝叶斯决策理论的角度来阐述,并可以证明,当两类数据同先验、满足高斯分布且协方差相等时,LDA可达到最优分类。
可将LDA推广到多分类任务。
多分类学习
多分类学习的基本思路是拆解法,即将多分类任务拆为若干个二分类任务求解 。最经典的拆分策略有三种,一对一(one vs one,OvO),一对其余(one vs rest,OvR),多对多(manay vs many,MvM)。
OvO将这N个类别两两配对,从而产生N(N-1)/2个二分类任务。
OvR则是每次将一个类的样例作为正例,所有其他类的样例作为反例来训练N个分类器。在测试时若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果。若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
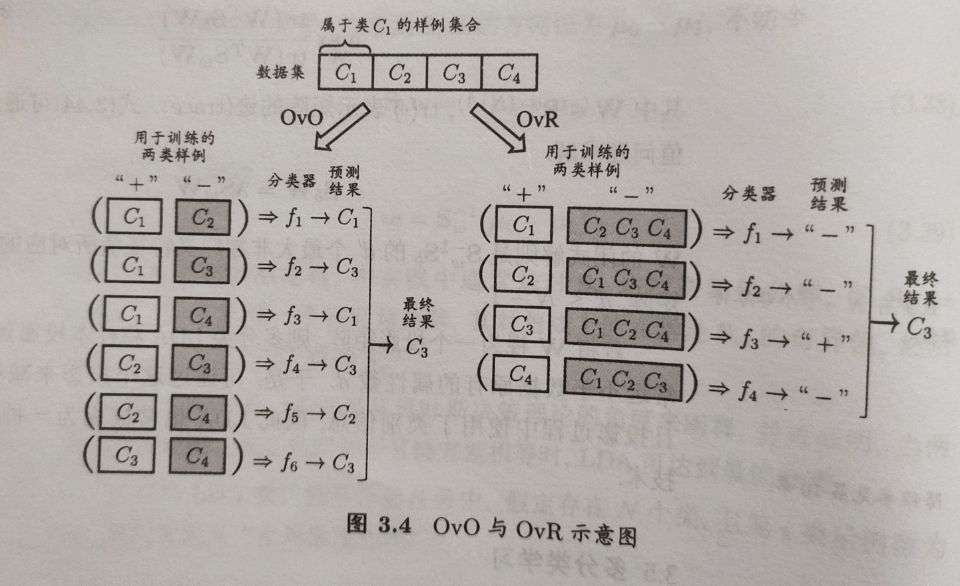
可以看出,OvR只需要训练N个分类器,而OvO需训练N(N-1)/2个分类器,因此,OvO的存储开销和测试时间开销通常比OvR大。但在训练时,OvR的每个分类器均使用全部训练样例,而OvO的每个分类器仅用到两个类的样例,因此,在类别很多时,OvO的训练时间开销通常比OvR更小。至于预测性能,多数情况下二者差不多。
介绍一种MvM最常用的技术,纠错输出码(Erroe Correcting Output Codes,ECOC),它是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性。EOOC工作过程主要分为两步:
编码:对N个类别做M次划分,每次划分将一部分划分为正类,一部分划分为反类,从而形成一个二分类训练器;这样一共产生M个训练集,可训练出M个分类器。
解码:M个分类器对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
对于同一个学习任务,EOOC编码越长,纠错能力越强。
类别不平衡问题
一个基本策略是再缩放。
大体有三种做法:
欠采样:去除一些样例使得正反例数目接近
过采样:增加一些样例使得正反例数目接近
第三类是基于原始数据训练,,再进行阈值转移。
欠采样法的时间开销通常远小于过采样。过采样法不能简单对初始样本进行重复采样,否则会过拟合。
决策树
基本流程
决策树学习基本算法

划分选择
信息增益
信息熵为度量样本集合纯度最常用的一种指标。假定样本集合D中第k类样本所占的比例为$p_k$,则D的信息熵定义为
Ent(D)的值越小,则D的纯度越高。
假定离散属性有v个可能的取值,若使用a来对样本集D进行划分,则会产生V个分支结点,其中第v个分支结点包括了D中所有在属性a上取值为$a^v$的样本,记为$D^v$。则可又获得信息增益:
著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性的。
X和Y的交互信息
样本熵:各类样本熵之和
增益率
但是,显而易见,信息增益准则对于可取数目较多的属性有所偏好,所以我们引入增益率。著名的C4.5决策树算法便是使用增益率来哈分最优划分属性的。增益率定义为
需要注意,增益率准则对于可取纸2数目较少的属性有所偏好,因此C4.5并不是直接使用增益率准则来进行划分的,而是采用了一个启发式算法,先从候选划分属性中zhaochu1信息增益高于平均水平的属性,再从中选择增益率最高的。
基尼系数
CART决策树采用基尼指数来选择划分属性。数据集D的纯度可用基尼系数来度量:
直观理解的话,基尼系数反应了从数据集D中随机抽取两个样本,其分类不一致的概率。
属性a的基尼系数定义为
剪枝处理
剪枝(pruning)是决策树学习算法对应过拟合的主要手段。决策树基本策略有预剪枝(prepruning)和后剪枝(postpruning)。
预剪枝是在决策树生成过程中,对每个结点在划分前进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该节点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
预剪枝使决策树很多分支都没有展开,降低了过拟合风险,减少了决策树训练时间开销和测试时间开销,但会带来欠拟合的风险。
后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。
连续与缺失值
连续值处理
由于连续属性的可取数目不再有限,因此不能直接根据连续属性的可取值来对结点进行划分。此时,连续属性离散化技术派上用处。最简单策略就是采用二分法,正是C4.5决策树算法采用的机制。
缺失值处理
在以下三方面影响到决策树构建
影响杂质测量计算方式;影响如何将缺失值的实例分配到子节点;影响具有缺失值的测试实例如何被分配
原信息增益=去除缺失值信息增益*(去除后的样本数/总样本数)
多变量决策树
每个节点划分为线性分类器。对属性的线性组合进行测试。
考点
基于决策树分类的优点
构建过程计算资源开销小;
分类未知样本速度极快;
对于小规模的树比较容易解释;
在许多小的简单数据集合性能与其他方法相近。
TOP-DOWN决策树

过拟合
pre-pruning
如果所有的实例都属于同一类别就停止;如果所有的属性值都一样就停止。
更加具有限制性的,如果实例的数量少于用户指定的阈值;如果实例的类别分布与可用的特征无关;如果扩展当前节点不能改善纯度。(基尼系数或信息增益)
post-pruning
将决策树增长到其全部内容,以自下而上的方式修剪。若修剪后泛化错误得到改善,则将子树替换为叶子。可使用MDL修剪。
MDL
最小描述长度准则—Minimum Description Length
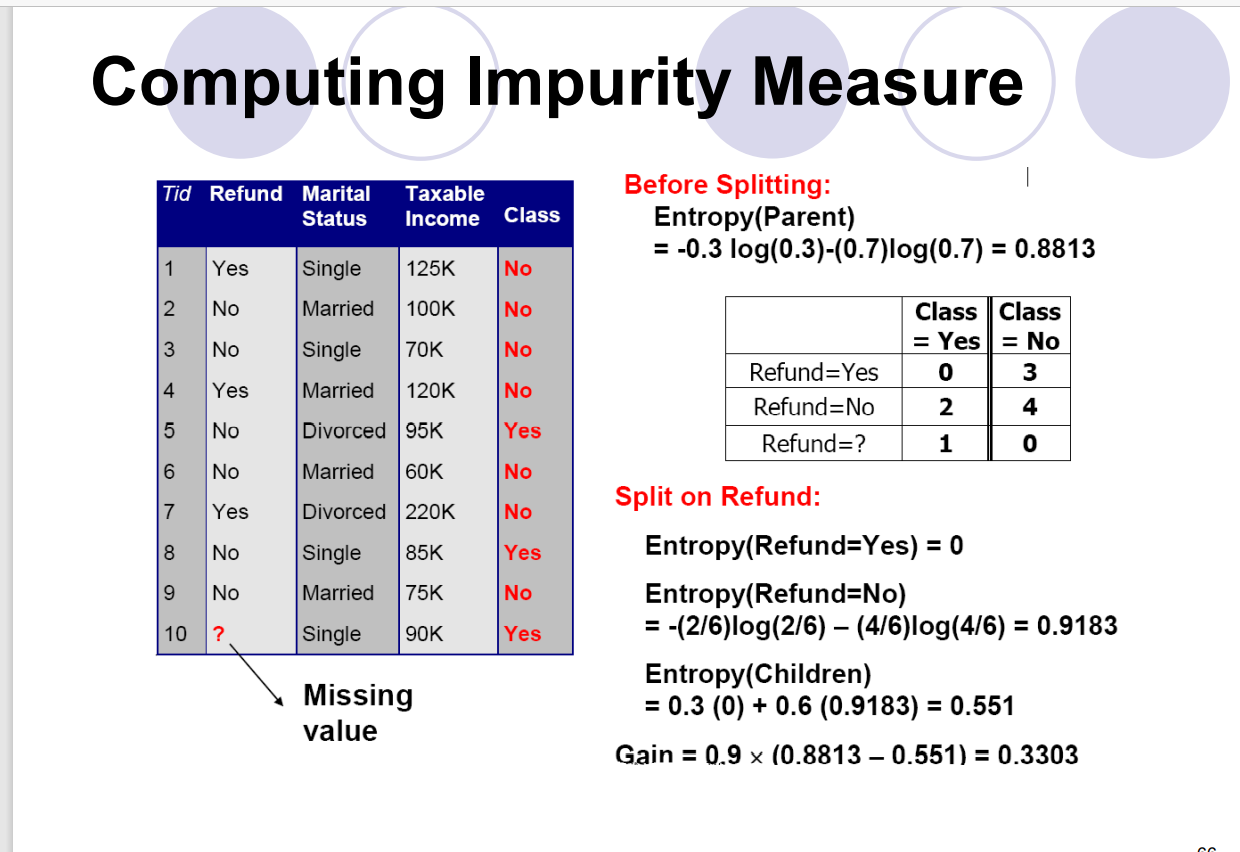
分发实例的过程,将缺失值按照权重分别分发给不同的分支。如下图:
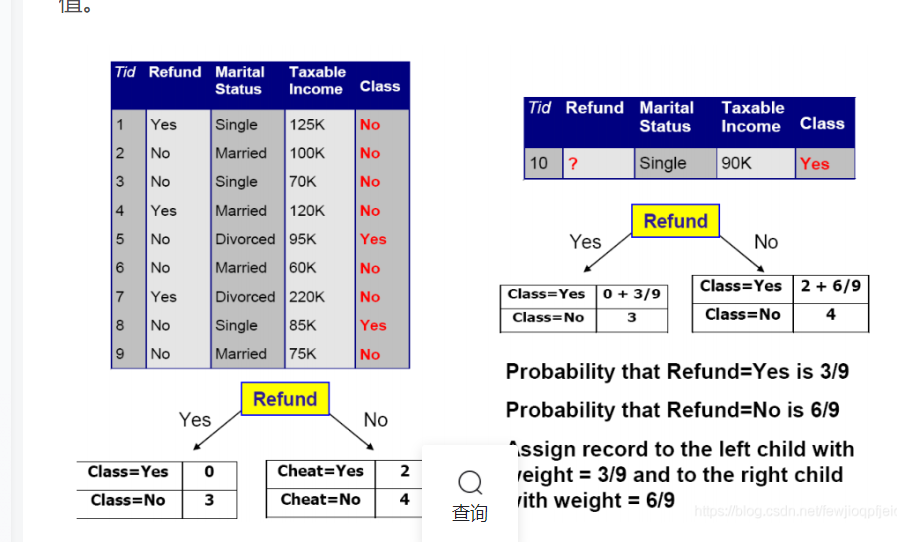
对于新实例有缺失值的情况下如何分类,也要利用概率来看。
惩罚项
惩罚项比重影响 :比重大时降低模型复杂度 ;比重适当时模型复杂度与问题匹配 ;比重小时、退化成原模型
支持向量机
support vector machine,SVM
间隔与支持向量
给定训练集样本D,分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面。
在样本空间中,划分超平面可通过如下线性方程来描述:$w^T x+b$
其中$w$为法向量,决定了超平面的方向,b为位移量。我们将该平面记做(w,b)
样本空间中任一点x到该超平面的距离可写为
假设超平面可将训练样本正确分类,对于$(x_i,y_i)$,若$y_i=1$,则有$w^T x+b>$0,若为-1则<0
令
如图所示,距离超平面最近的这几个训练样本使上述等号成立,他们被称为支持向量,两个异类支持向量,两个异类支持向量到超平面的距离之和为$\gamma=\frac{2}{||w||}$,它被称为间隔。
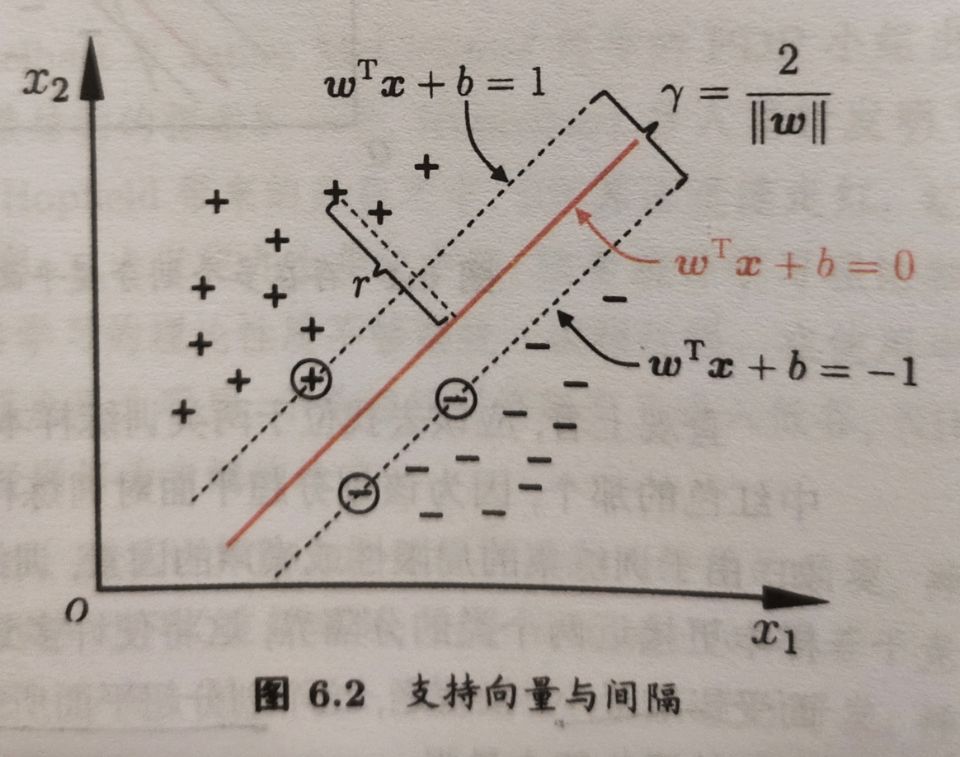
想要找到最大间隔,即找到最大$w与b$,使得$\lambda$最大。
显然,为了最大化间隔,仅需要最大化$||w||^{-1}$,这等价于最小化$||w||^2$,于是便有
这就是SVM的基本型。
对偶问题
对于SVM的基本型,添加拉格朗日乘子$\alpha\ge0$,则该问题拉格朗日函数可以写为
其中$\alpha_i=(\alpha_1,\alpha_2,…,\alpha_m)$
分别求偏导,$w=\sum{i=1}^{m}\alpha_i y_i x_i,0=\sum{i=1}^{m}\alpha_i y_i$
代入,可得对偶问题如下
解出$\alpha$后,求出w与b即可得到模型
因为上述过程需要满足KK条件,即要求
$\alpha_i\ge0$
$y_if(x_i)-1\ge0$
$\alpha_i(y_if(x_i)-1)=0$(13)
若$\alpha_i$=0,则该样本不会在12的求和中出现,也就不会对f(x)有影响‘
若后面等于0,则所对应的样本点位于最大间隔边界上,是一个支持向量。
如何求解11呢?我们介绍一种高效的SMO算法。
暂且跳过这部分。
核函数
若在原始样本空间内不存在一个能正确划分两类样本的超平面,面对这类问题,我们可将样本从原始空间映射到一个高维的特征空间,使得样本在这个高维空间内线性可分。并且若原始空间有限,则一定存在一个高维特征空间使样本可分。
令$\phi(x)$表示将x映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可以表示为
$f(x)=w^T\phi(x)+b$
同上,其对偶问题是
求解21会涉及到计算$\phi(x_i)^T\phi(x_i)$,这是样本$x_i与x_j$映射到特征空间后的内积,计算困难,为了避开这个障碍,可以设想一个这样的函数
即$x_i与x_j$在特征空间的内积等于他们在原始样本空间中通过函数$\kappa$计算的结果。
则可进行求解,求解得
这里的$\kappa(,)$就是核函数,24显示出模型最优解可通过训练样本的核函数展开,这一展开式也称为“支持向量展式”。
关于核函数,我们有以下定理:
暂且略过
软间隔与正则化
大多数时候我们很难找到合适的核函数,所以为了缓解这一问题,我们会允许支持向量机在一些样本上出错。为此要引入软间隔的概念。
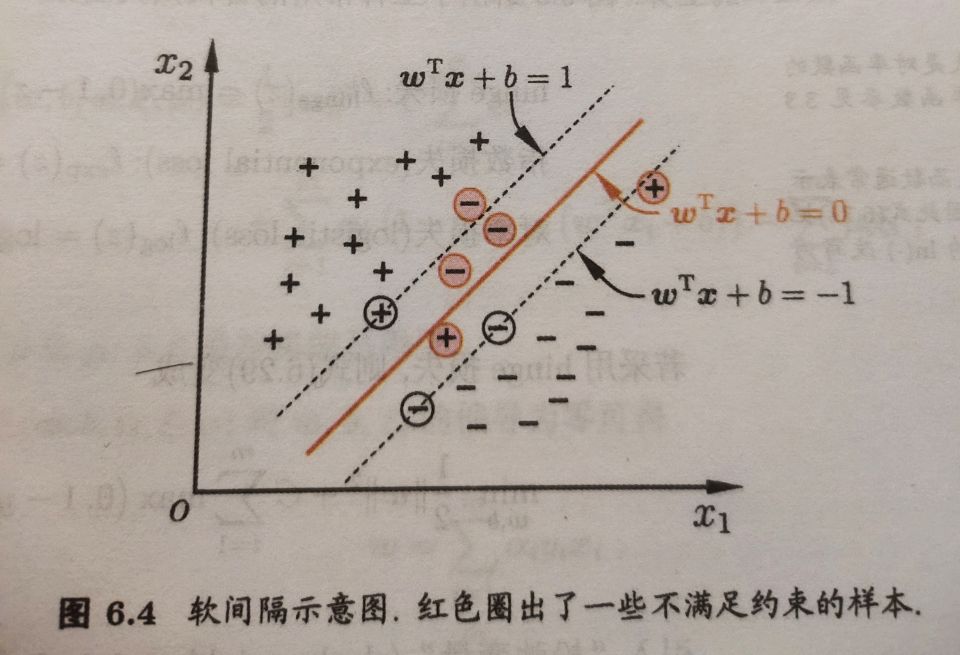
软间隔则是允许某些样本不满足约束
$y_i(w^Tx_i+b)\ge1$(28)
当然,在最大化间隔的同时,不满足约束的样本应尽可能少。于是,优化目标可以写为
贝叶斯分类器
贝叶斯决策论
[最大后验估计(Maximum-a-Posteriori (MAP) Estimation) ]
最大似然估计(MLE)选择值 使观察到的数据的概率最大化
最大后验估计(MAP) 选择在观察到的数据和先验条件下最有可能的值
缺点
MLE: 如果数据集太小,就会过度拟合
MAP: 两个有不同预设的人最终会导致不同的估计值



极大似然估计


朴素贝叶斯分类器

半朴素贝叶斯分类器

其中$pa_i$为属性$x_i$所依赖的属性,称为$x_i$的父属性。问题的关键转换为如何确定每个属性的父属性,不同的做法产生不同的独依赖分类器。
最直接的做法是假设所有属性都依赖于同一个属性,称为“超父”,然后通过交叉验证等模型选择方法来确定超父属性,由此形成了SPODE(Super-Parent ODE)方法,例如(b)中,$x_1$是超父属性。
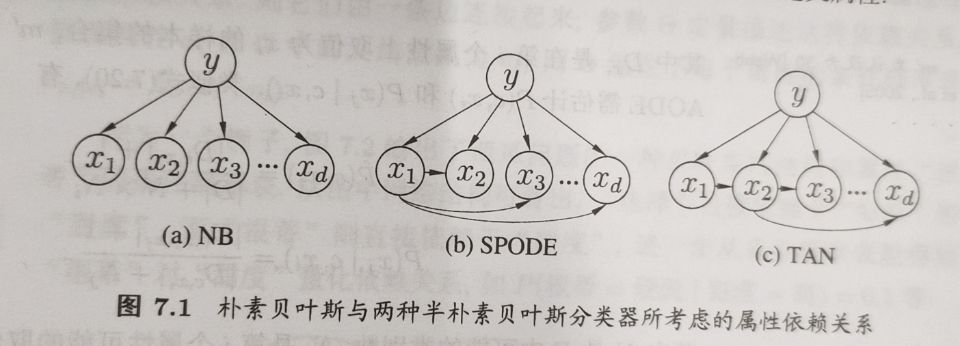
TAN则是在最大带权生成树算法的基础上,通过以下步骤化简为(c)的树形结构。

贝叶斯网
Directed Acyclic Graph(DAG):有向无环图
Conditional Probability Table(CPT):条件概率表
具体来说,一个贝叶斯网B由结构G和参数$\theta$两部分构成,即$B=
网络结构G为DAG,其每个结点对应于一个属性,若两个属性有直接依赖关系,则他们由一条边连接起来;参数$\theta$定量描述这种依赖关系,假设属性$xi$在G中的父节点为$\pi_i$,则$\theta$包含了每个属性的条件概率表$\theta{x_i|\pi_i}=P_B(x_i|\pi_i)$
结构
给定父节点集,贝叶斯网假设每个属性与它的非后裔属性独立。
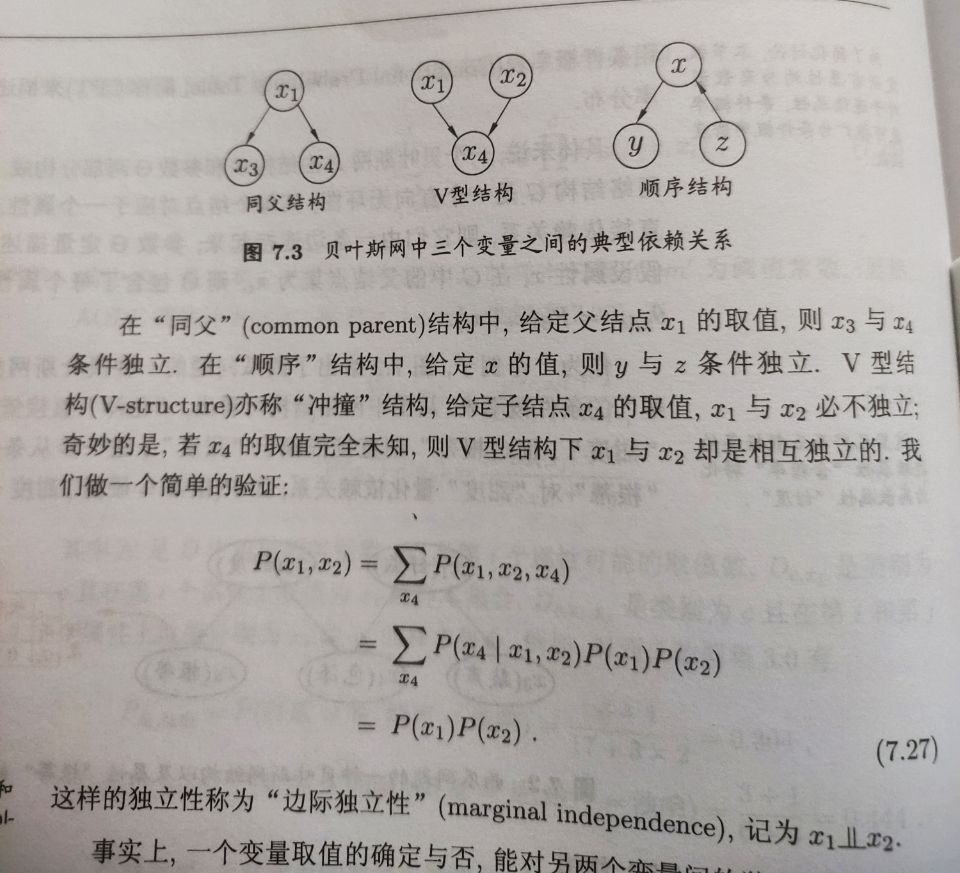
为了分析有向图中变量间的条件独立性,可使用有向分离。我们先把有向图转变成为一个无向图:
*找出有向图中的所有V型结构,在V型结构的两个父节点之间加上一条无向边;
*将所有有向边改为无向边
由此产生的无向图称为道德图,令父节点相连的过程称为道德化。
若变量x和y能在图上z分开,即从道德图中将变量集合z去除后,x和y分属两个连通分支,则称x和y被z有向分离,$x\perp y|z$成立。
学习
贝叶斯网学习的首要任务就是根据训练数据集来找出结构最恰当的贝叶斯网。评分搜索是求解这一问题的常用办法。具体来说,我们先定义一个评分函数,以此来评估贝叶斯网与训练数据的契合程度,然后基于这个评分函数来寻找结构最优的贝叶斯网。
常用评分函数通常基于信息论准则,此类准则将学习问题看作一个数据压缩任务,学习的目标是找到一个能以最短编码长度描述训练数据的模型,此时编码的长度包括了描述模型自身所需的编码位数和使用该模型描述数据所需的编码位数。对于贝叶斯网学习而言,模型就是一个贝叶斯网,同时,每个贝叶斯网描述了一个在训练数据上的概率分布,我们应选择那个综合编码长度最短的贝叶斯网,这就是最小描述长度准则。(Minimal Description Length,MDL)
给定训练集D,贝叶斯网$B=
其中,|B|是贝叶斯网的参数个数;$f(\theta)$表示描述每个参数$\theta$所需的编码位数。而
是贝叶斯网B的对数似然。显然,28的第一项是计算编码贝叶斯网B所需的编码位数,第二项是表述B所对应的概率分布$P_B$对D的描述有多好。此时,学习任务转换为优化任务,寻找一个贝叶斯网B使得评分函数最小。
若$f(\theta)=1$,则得到AIC评分函数。
若$f(\theta) =\frac12log\ m$,则得到BIC评分函数。
当=0时,评分函数退化为负对数似然函数,学习任务退化为极大似然估计。
为最小化评分函数,只需要对网络结构进行搜索,而候选结构的最优参数可直接在训练集计算得到。
但是,在所有可能的网络空间搜索最优贝叶斯网络是一个NP问题。一般有两种策略在有限时间内求得近似解,第一种为贪心法,第二种是通过给网络结构施加约束来削减搜索空间。
推断
贝叶斯网络的近似推断常使用吉布斯采样来完成,这是一种随机采样方法。


EM算法
在现实中,会存在许多未观测变量。未观测变量的学名是隐变量,令X表示已观测变量集,Z表示隐变量集,$\theta$表示模型参数,若想要对$\theta$做极大似然估计,则应最大化对数似然
$LL(\theta|X,Z)ln\ P(X,Z|\theta)$
由于Z是隐变量,我们可通过对Z计算期望,来最大化已观测数据的对数“边际似然”
$LL(\theta|X)=ln\ P(X|\theta)=ln\sum_{Z}P(X,Z|\theta)$(35)

聚类
聚类任务
在无监督学习中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务应用最广的是聚类。
聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个簇。

性能度量
聚类性能度量也称为聚类“有效性指标”。
聚类性能度量大致有两类,一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。


距离计算
对函数$dist$,若他是一个距离度量,则需要满足一些基本性质
非负性:$dist(x_i,x_j)\ge0$
同一性:$dist(x_i,x_j)=0当且仅当x_i=x_j$
对称性
直递性
对于给定样本
最常用的闵可夫斯基距离
当p=2时,闵可夫斯基距离即为欧氏距离
当p=1时,闵可夫斯基距离即为曼哈顿距离
定义域为{1,2,3}这样的属性为有序属性,而定义域为{飞机,轮船,火车}则为无序属性,闵可夫斯基距离用于有序属性。
对无序属性可采用VDM(Value Difference Metric)。令$m{u,a}$表示属性u上取值为a的样本数,$m{u,a,i}$表示在第i个样本簇中在属性u上取值为a的样本数,k为样本簇数,则属性u上两个离散值a与b之间的VDM距离为
于是,将闵可夫斯基距离和VDM结合即可处理混合属性。假定有$n_c$个有序属性、$n-n_c$个无序属性,不失一般性,令有序属性排列在无序属性之前,
当空间中不同属性的重要性不同时,可使用加权距离。
需要注意的是,通常我们是基于某种形式的距离来定义“相似度度量”,距离越大,相似度越小,然而用于相似度度量的距离未必一定要满足距离度量的所有基本性质。不满足直递性的距离称为非度量距离。
原型聚类
也称为基于原型的聚类,此类算法假设聚类结构能通过一组原型刻画。通常对原型进行初始化,然后对原型进行迭代更新求解。
k均值算法
给定样本集$D={x_1,x_2,..,x_m}$,“k均值”算法针对聚类所得簇划分$C={C_1,C_2,…,C_k}$最小化平方误差
k均值算法采用了贪心策略,通过迭代优化来近似求解式。
学习向量量化
Learning Vector Quantization(LVQ)与一般的聚类算法不同,LVQ假设数据样本带有标记类别,学习过程利用样本的这些监督信息来辅助聚类。
给定样本集
每个样本$xj$是由n个属性描述的特征向量$(x{j1};x{j2};…;x{jn})$,$y_i\in \gamma$是样本$x_j$的类别标记。LVQ的目标是学得一组n维向量${p_1,p_2,…,p_n}$,每个原型向量代表一个聚类簇,簇标记$t_i \in \gamma$。

高斯混合模型
参考下面这篇文章
https://zhuanlan.zhihu.com/p/30483076
密度聚类
此类算法假设聚类结构能通过样本分布的紧密程度确定。
DBSCAN是一种著名的密度聚类算法,它基于一组“邻域”参数$(\varepsilon,MinPts)$来刻画样本分布的紧密程度。给定数据集$D={x_1,x_2,…,x_m}$,定义以下概念
$\varepsilon-$邻域:对于x,其$\varepsilon$邻域包含样本集D中与$x_j$的距离不大于$\varepsilon$的样本
核心对象:若x的$\varepsilon$邻域至少包含MinPts个样本,则为一个核心对象
密度直达:若$x_j$位于$x_i$的$\varepsilon$邻域中,且$x_i$是核心对象,则称$x_j$由$x_i$密度直达
密度可达:对$x_i$与$x_j$,若存在样本序列
其中$p1=x_i,p_n=x_j$且$p{i+1}$由$p_i$密度直达,则称$x_j$由$x_i$密度可达
密度相连:对$x_i$与$x_j$,若存在$x_k$使得$x_k$使得二者均由$x_k$密度可达,则称二者密度相连。
DBSCAN将簇定义为:由密度可达关系导出的最大的密度相连样本集合。

层次聚类
层次聚类试图在不同层次上对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自顶向上”的聚合策略,也可采用“自顶向下”的分拆策略。
AGNES是一种采用自底向上聚合策略的层次聚类算法。它先将数据集中的每个样本看作一个初始聚类簇,然后在算法运行的每一步中找出距离最近的两个聚类簇进行合并。
当聚类簇距离由
计算时,AGNES算法被相应地称为单链接,全链接和均链接算法。

降维与度量学习
k近邻学习
k-Nearest Neighbor,简称kNN学习是一种常用的监督学习方法。
其工作机制是:给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本,然后基于这k个邻居的信息来进行预测。
k近邻学习没有显示的训练过程,是“懒惰学习”的主要代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为0,待收到测试样本后再进行处理;相应的,那些在训练阶段就对样本进行学习处理的方法称为急切学习。
k近邻的错误率小于贝叶斯的两倍。
低维嵌入
通过某种数学变换将原始高维属性空间转变为一个低维子空间。
若要求原始空间中样本之间的距离在低维空间中得以保持,即得到多维缩放(Multiple Dimensional Scaling,MDS)这样一种经典的降维方法。
主成分分析
Principal Component Analysis,PCA