序
NLP任务:分词、词性标注、未登录词识别
语言的性质:共时性;历时性
语法单位
1 | 句子是语言中最大的语法单位 |
语料库
• 语料库(corpus)一词在语言学上意指大量的文本,通常经过整理, 具有既定格式与标记
语料库的种类
1 | 共时语料库与历时语料库 |
语料加工
文本处理
1 | 垃圾格式问题 |
格式标注
1 | 通用标记语言SGML |
Zipf法则 • 一个词地频率f和它的词频排序位置r: f*r=k (k为常数)
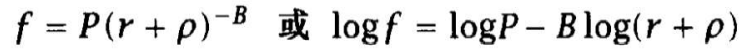
如果设置参数B=1, ρ=0,Mandelbrot公式就简化为Zipf法则
搭配抽取

语料库加工_双语句子自动对齐& 双语词典获取
句子对齐问题描述
基于长度的句子对齐 基本思想:源语言和目标语言的句子长度存在一定 的比例关系
要求:最小(句珠内无句珠); 唯一(一个句子仅属于一个句珠); 无交叉(后句对齐一定在前句对齐位置之后)
基于共现的双语词典的获取
基本思想:如果汉语词出现在某个双语句对 中,其译文也必定在这个句对中。
汉英词典的迭代获取策略
1 | 迭代策略 |
基于共现的词汇对译模型
评价方式:专家独立于上下文进行判别
1 | 评价1:每5000个翻译词对候选中正确的译文数 |
汉语自动分词
词法分析
词干提取vs词形还原:分别用于IR 和 NLP
1 | 词干提取(stemming)是抽取词的词干或词根形式(不一定能够表达完整语义 |
1 | 词干提取主要是采用“缩减”的方法 |
词性标注
1 | 词性标注(part-of-speech tagging),又称为词类标注或者简称 |
分词算法
正向最大匹配分词(Forward Maximum Matching method, FMM)
1 | 基本思想:将当前能够匹配的最长词输出 |
逆向最大匹配分词(Backward Maximum Matching method, BMM法
1 | 分词过程与FMM方法相同,不过是从句子(或文 |
实验表明:逆向最大匹配法比最大匹配法更有效
最大匹配法的问题
1 | • 存在分词错误:增加知识、局部修改 |
双向匹配法(Bi-direction Matching method, BM法)
1 | 双向最大匹配法是将正向最大匹配法(FMM)得到的分词 |
最少分词法
1 | • 分词结果中含词数最少 |
分词问题:歧义
交集型切分歧义
1 | 汉字串AJB被称作交集型切分歧义,如果满足AJ、JB同时 |
组合型切分歧义
1 | • 汉字串AB被称作组合型切分歧义,如果满足条件:A、 |
交集型歧义字段中含有交集字段的个数,称为链长
“真歧义”和“伪歧义”
1 | • 真歧义指存在两种或两种以上的可实现的切分形式 |
分词问题
1 | 歧义 |
分词质量评价

中文分词_统计建模
基于N元文法的分词(MM)
MM(马尔可夫模型/过程) :有限历史假设,仅依 赖前n-1个词
一种最简化的情况:一元文法
1 | P(S)=p(w1) ·p(w2) ·p(w3)….p(wn) |
采用二元语法(bi-gram):性能进一步提高
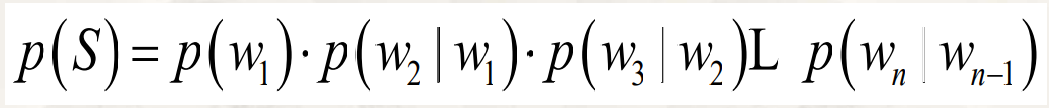
更大的n:对下一个词出现的约束性信息更多,更大的辨别力。 更小的n:出现的次数更多,更可靠的统计结果,更高的可靠性。
等价类映射:降低语言模型参数空间
数据平滑(smoothing):保持模型的辨别能力
基于HMM的分词/词性标注一体化
输入:待处理句子S
输出:S的 词序列 W = w1 ,w2…wn
词性序列 T = t1 ,t2…tn
提示 W可以代表S 分词结果即观测序列 词性序列是状态序列
公式推导

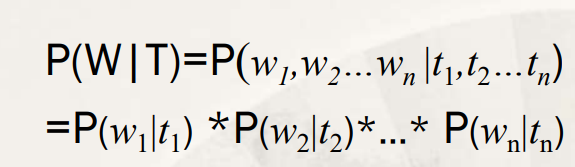
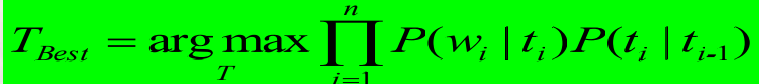
由字构词的汉语分词方法
基本思路 分词过程:一个字的分类问题; 每个字在词语中属于一个确定位置
字的的标注过程中,对所有的字根据预定义的特 征进行词位特征学习,获得一个概率模型
由字构词的分词技术的优势
1 | 简化了分词系统的设计 文本中的词表词和未登录词都是用统一的字 标注过程来实现的,分词过程成为字重组的 简单过程。 既可以不必专门强调词表词信息,也不用专 门设计特定的未登录词识别模块 |
汉语分词方法的后处理方法
为什么不采用更精巧的模型?
1 | 四元或更高阶... 不可行,需要大量的参数 不得不做一些平滑或差值 难度随模型复杂度而加剧 |
两个重要组成部分:
1 | 允许的错误校正转换的详细说明 |
输入数据
1 | 一个已经标注好的语料库, |
基于转换错误驱动的规则方法
1 | 学习和标注在该方法种都是简单和直观的 |
标注可以采用
1 | 隐马尔科夫模型(HMM) 最大熵(ME) 最大熵马尔科夫模型(MEMM) 条件随机场(CRF)等 |
隐马尔科夫模型
马尔科夫(Markov)模型
马尔科夫模型是一种统计模型,广泛的应用在语音识别, 词性自动标注,音字转换,概率文法等各个自然语言处理 的应用领域。
随机过程又称为随机函数,是随时间随机变化的过程。马 尔科夫模型描述了一类重要随机过程。
系统在时间t处于状态𝑠𝑗的概率取决于其在时间1,2,…t-1的 状态,该概率为:
1 | 𝑃(𝑞𝑡 = 𝑠𝑗|𝑞𝑡−1 = 𝑠𝑖, 𝑞𝑡−2 = 𝑠𝑘, … ) |
离散的一阶马尔科夫链:系统在时间t的状态只与时间t-1 的状态有关。
1 | 𝑃(𝑞𝑡 = 𝑠𝑗|𝑞𝑡−1 = 𝑠𝑖, 𝑞𝑡−2 = 𝑠𝑘, … ) = 𝑃(𝑞𝑡 = 𝑠𝑗|𝑞𝑡−1 = 𝑠𝑖) |
状态转移概率𝑎𝑖𝑗必须满足以下条件:
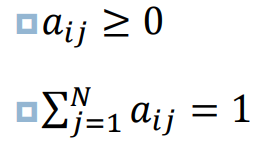
N个状态的一阶马尔科夫过程有𝑁2,可以表示成为一个状 态转移矩阵
eg:状态𝑠1:名词 状态𝑠2:动词 状态𝑠3:形容词
如果在该文字中某句子的第一个词为名词,那么该句子 中三类词出现顺序为O=“名动形名”的概率。
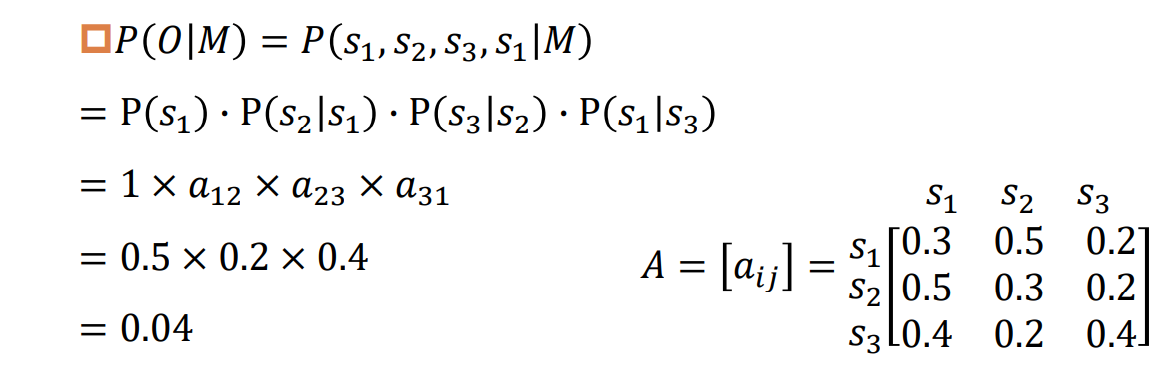
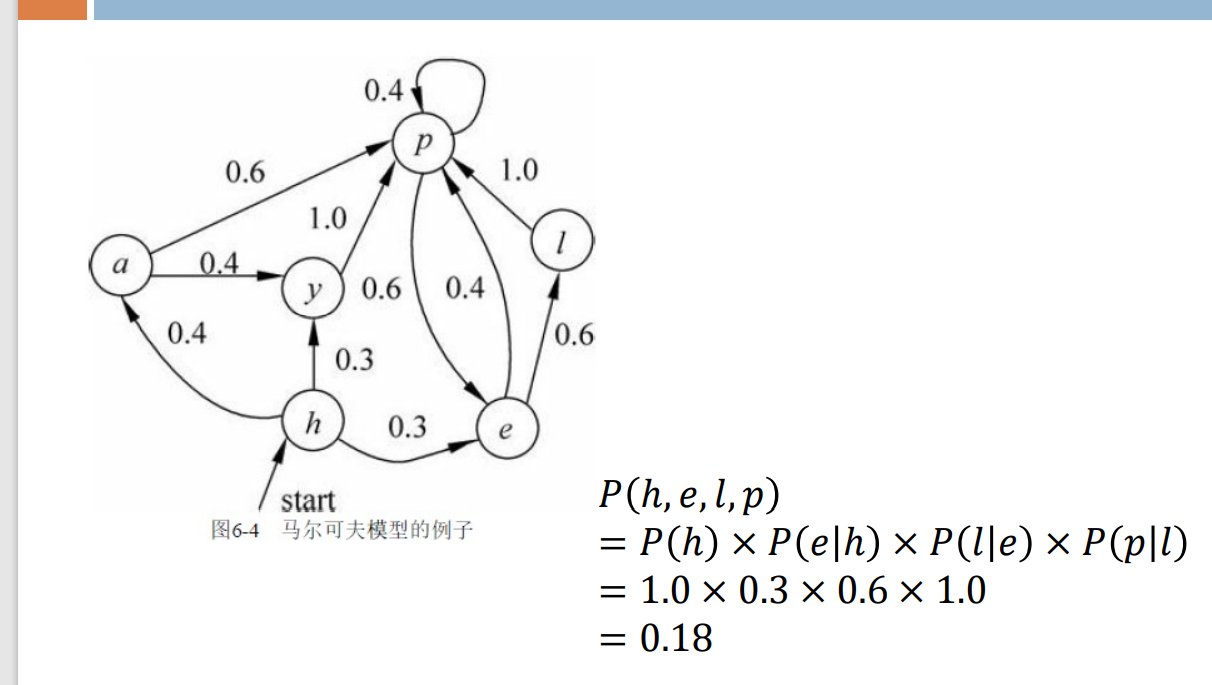
马尔科夫(Markov)模型:有限状态机
1 | 马尔科夫模型可视为随机的有限状态机。 |
eg:
一般地,一个HMM记为一个五元组μ=(S,K, A,B,π),其中,S为状态的集合,K为输出符 号的集合,π,A和B分别是初始状态的概率分布、 状态转移概率和符号发射概率。为了简单,有时也将其记为三元组μ=(A,B,π)
隐马尔可夫模型:三个基本问题
1 | 1.估值问题:给定一个观察序列 O = 𝑂1𝑂2 … 𝑂𝑇 和模型μ=(A, |
隐马尔可夫模型:求解观察序列的概率
1 | 给定观察序列O = 𝑂1𝑂2 … 𝑂𝑇和模型𝜇 =(𝐴, 𝐵, π),快速的计算出给定模型𝜇情况下观察序列O的概率,即𝑃 (𝑂|𝜇) 。 |

隐马尔可夫模型:前向算法
1 | 基本思想:定义前向变量𝛼𝑡(𝑖),前向变量𝛼𝑡(𝑖)是在时间t,HMM输出了序列𝑂1𝑂2 … 𝑂𝑡 ,并且位于状态𝑠𝑖的概率。 |
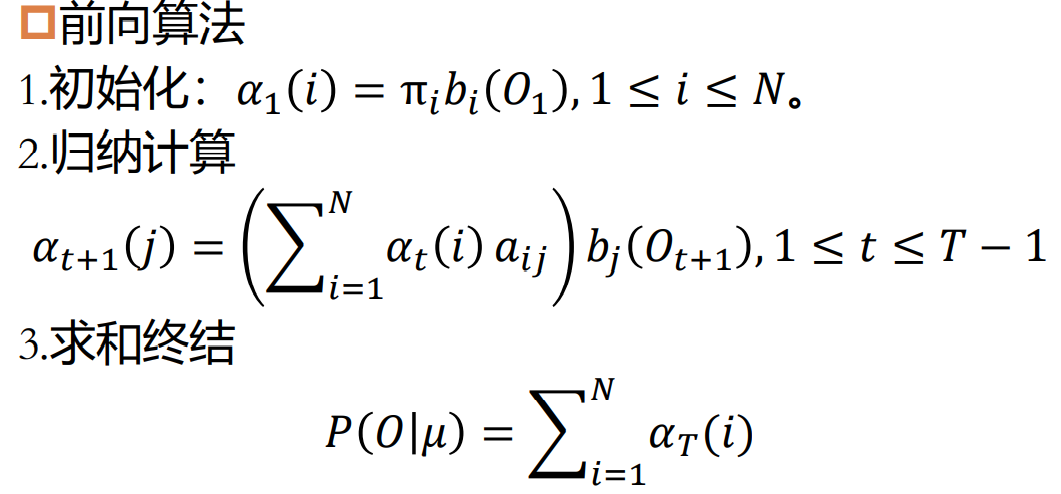
前向算法总的复杂度为O(𝑁2𝑇)
隐马尔可夫模型:后向算法
1 | 后向变量𝛽𝑡(𝑖)是在给定模型𝜇 = (𝐴, 𝐵, π),并且在时间t状态为𝑠𝑖的条件下,HMM输出观察序列𝑂𝑡+1 … 𝑂𝑇的概率。 |
与计算前向变量一样,可以用动态规划的算法计算后向变量。

时间复杂度:O(𝑁2𝑇)
序列问题
隐马尔可夫模型:维特比算法
1 | 维特比算法用于求解HMM中的第二个问题,给定一个观 |


存在问题
1 | 单独最优不一定整体最优 |
参数估计
最 大似然估计
EM
句法分析
句法分析概述
基本任务:确定句子的句法结构或句子中词汇之间的依存关系。
定义:判断单词序列(一般为句子)判读其构成是否合乎 给定的语法(recognition),如果是,则给出其(树)结构 (parsing)
描述一种语言可以有三种途径
1 | 穷举法:把语言中的所有句子都枚举出来。显然,这种方法只适合句子数目有限的语 |
形式语法
1 | 四元组 𝐺 = {𝑁, Σ, 𝑃, 𝑆} |
形式语法种类
1 | 正则文法 |
控制策略
1 | 自顶向下、自底向上 |
搜索策略
1 | 深搜广搜 |
扫描策略
1 | 自左至右,自右至左 |
移进-归约是自底向上语法分析的一种形式
CFG缺陷
1 | 对于一个中等长度的输入句子来说,要利用大覆盖度的语法规 |
概率上下文无关文法(PCFG)
概率上下文无关文法就是一个为规则增添了概率的简单CFG, 指明了不同重写规则的可能性大小
在基于PCFG的句法分析模型中,假设满足以下三个条件:
1 | 上下文无关性 |
剪枝策略:Beam search(集束搜索)
1 | 一种启发式图搜索算法,为了减少搜索占用的时间和空间,在每一步深度扩展的时候, |
PCFG的优点
1 | 可利用概率减少分析过程的搜索空间 |
PCFG的缺陷
1 | 结构相关性 |
词义消歧
word sense disambiguation WSD
义位:语义系统中能独立存在的基本语义单位
WSD需要解决三个问题:
1 | (1)如何判断一个词是不是多义词? 如何表示一个多义词的不同意思? |
1 | 基于机器词典的WSD |
1 | 总结: |
基于义类词典的WSD方法

互信息:I(X;Y)反映的是在知道了Y的值 以后X的不确定性的减少量。
基于Bayes判别的WSD方法

词义消歧——基于多分类器集成
1 | 总结 |
篇章
概念
1 | Anaphor:指代语 |
六类指称表示
1 | Indefinite NPs(不定名词): 一辆汽车 |
指代一般包括两种情况
1 | – 回指(Anaphora):强调指代语与另一个表述之间的关 |
衔接和连贯
以词汇表示的关联,通常称为“衔接(cohesion),强调其构成成分
通过句子意义表示的关联称为连贯Coherence,强调整体上表达某种意义
篇章表示和相似度计算
将文档表示为如下所示的向量: 𝑑𝑗 = (𝑤1,𝑗 , 𝑤2,𝑗 , 𝑤3,𝑗 , … , 𝑤𝑡,𝑗) 向量的每一维都对应于词表中的一个词。 如果某个词出现在了文档中,那它在向量中的值就非 零。 这个值有很多计算方法,我们使用词语在文档中出现 的次数表示。
机器翻译
传统机器翻译方法
1 | 直接翻译法 |
基于规则的翻译方法
1 | 对源语言和目标语言均进行适当描述 |
1 | ▪优点: |
基于实例的翻译方法
1 | 方法:输入语句->与事例相似度比较->翻译结果 |
1 | ▪ 方法优点 |
基于统计的机器翻译模型
噪声信道模型
1 | 一种语言T 由于经过一个噪声信道而发生变形从而在信道的另一端呈现为另一种语言 S |
翻译问题可定义为:
1 | ▪ 如何根据观察到的 S,恢复最为可能的T 问题。 |

▪三个关键问题 ▪ (1)估计语言模型概率 p(T); ▪ (2)估计翻译概率 p(S|T); ▪ (3)快速有效地搜索T 使得 p(T)×p(S | T) 最大
基于词的统计机器翻译模型
IBM模型1:词汇翻译(词对齐)
1 | ▪ 基于词的统计翻译模型 |
IBM模型2:增加绝对对齐模型
IBM模型3:引入繁衍率模型
1 | 前述模型存在的问题 |
繁衍率
1 | 定义:与目标语言句子中的单词t对应的源语言句子中的单词数目的变量 |
基于短语的统计机器翻译模型
基本思想
1 | ▪ 把训练语料库中所有对齐的短语及其翻译概率存储起来,作为一部带 |
系统融合
几个相似的系统执行同一个任务时,可能有多个输出结果,系统融合将这些结果进行融 合,抽取其有用信息,归纳得到任务的最终输出结果。
目标:最终的输出比之前的输入结果都要好
句子级系统融合
1 | 两种技术 |
句子级系统融合方法不会产生新的翻译句子,而是在已有的翻 译句子中挑选出最好的一个
短语级系统融合 ▪ 利用多个翻译系统的输出结果,重新抽取短语翻译规则集合,并利用 新的短语翻译规则进行重新解码
1 | 基本思想:首先合并参与融合的所有系统的短语表,从中抽取 |
词语级系统融合 ▪ 首先将多个翻译系统的译文输出进行词语对齐,构建一个混淆网络, 对混淆网络中的每个位置的候选词进行置信度估计, 最后进行混淆网 络解码
小结
1 | 句子级系统融合 |
应用:语言自动生成
自然语言生成概述
NLG生成模型
1 | 1. 马尔可夫链:通过当前单词可以预测句子中的下一个单 |
数据到文本的生成
以包含键值对的数据作为输入,旨在 自动生成流畅的、贴近事实的文本以描 述输入数据。
1 | 信号分析模块(Siganl Analysis) |
应用领域:
1 | 天气预报领域的文本生成系统 |
文本到文本的生成
对给定文本进行变换和处理从而获得新文本的技术
应用
1 | 对联自动生成 |
词和文档表示与相似度计算
词的表示
独热表示
1 | 每个词对应一个向量,向量的维度等于词典的大小,向量中只有一个元素值为1,其余的元素均为0 ,值为1的元素对应的下标为该词在词典中的位置 |
词频 -逆文档频率(TF -IDF)
词嵌入方法的问题
1 | 静态词向量 |
词向量
skip-gram
1 | 1. 将目标词和邻近的 |
文档表示
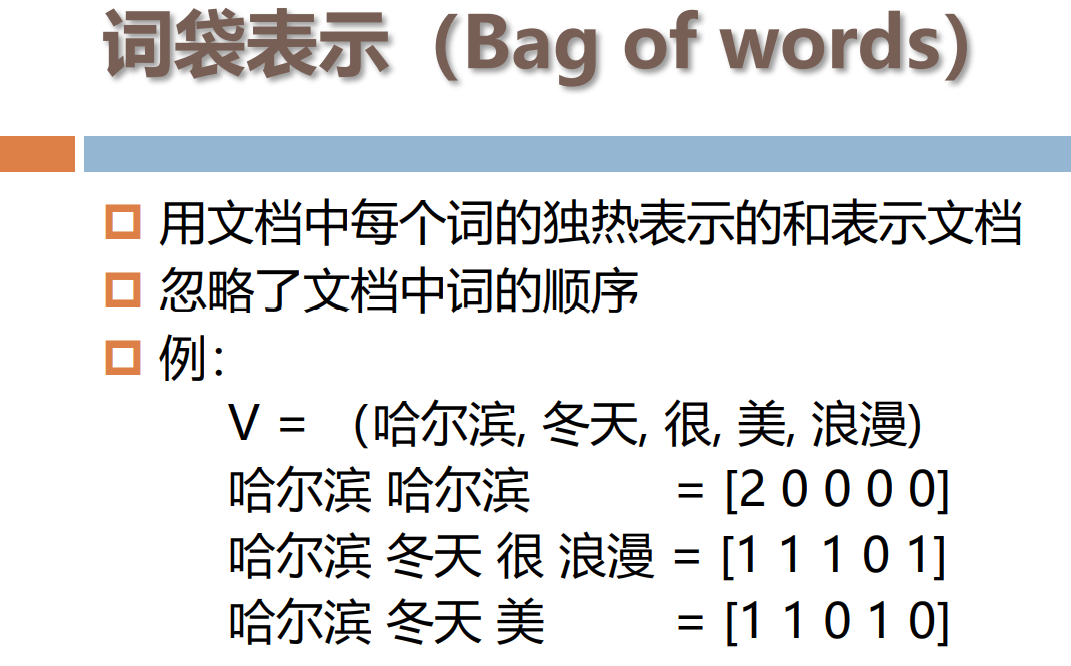
文本相似度计算
编辑距离,动态规划
信息抽取
信息抽取的定义、任务及发展
信息抽取中的主要任务
1 | 命名实体识别: |
命名实体识别
挑战
1 | 种类繁多,命名方式灵活多样 |
主要方法
1 | 基于规则的方法 基于词典的方法 机器学习方法 ◼最大熵 ◼条件随机场 ◼深度学 |
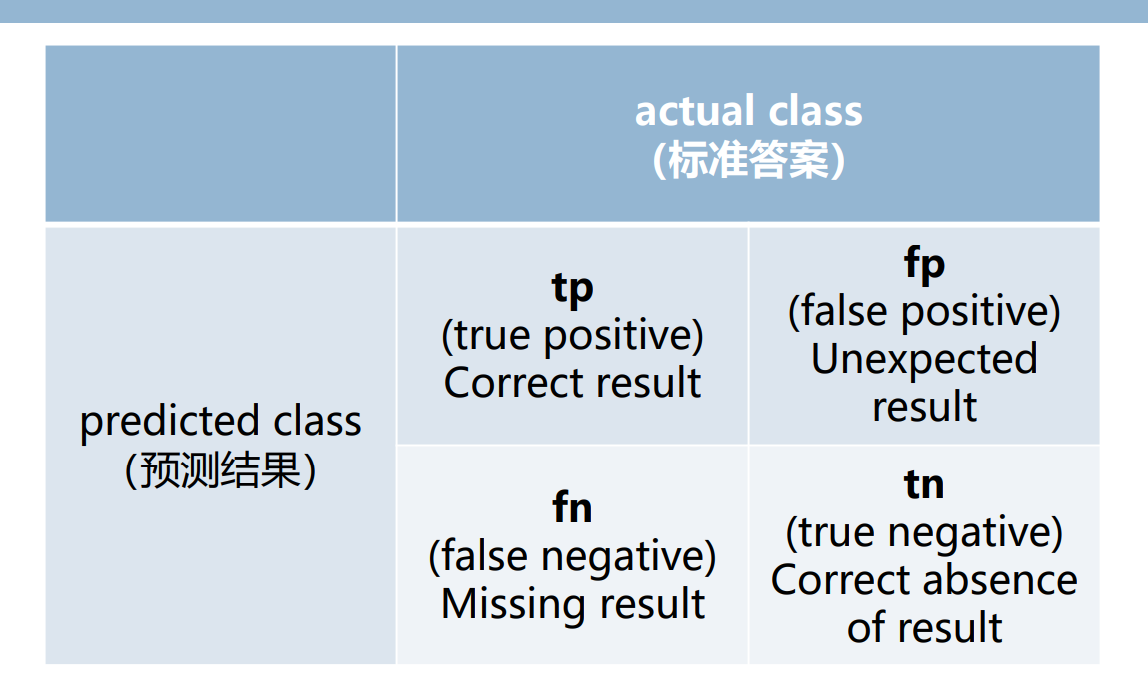
命名实体识别的评价

实体链接
将“实体提及”链接到知识库中对应的实体
关系抽取
自动识别由一对实体和联系这对实体的关系构成的 相关三元组
预定义关系抽取
1 | 任务 |
基于神经网络的关系抽取方法
1 | 主要问题:如何设计合理的网络结构,从而捕捉更多的信息,进而更准确的完成关系的抽取 |
开放域关系抽取
1 | 实体类别和关系类别不固定、数量大 |
深度学习简介
常用的深度学习模型
1 | 激活函数 |
pooling
1 | 目的: |
深度学习模型的应用
1 | DBN的应用 |