进程运行轨迹的跟踪与统计
实验步骤
1.修改init/main.c文件。
由于新改版的实验环境,打印进程 0 的相关内容会产生bug,可能是虚拟机或是其他原因引起的。 因此,后续所有的打印输出都是从进程 1 开始,所以对于init/main.c文件,将在进程1的关联代码后边补充打开log文件的代码。
修改如下:

如果要是按照之前版本进行修改,则进入linux0.11后,会一直在task[0]进行空转,血的教训,浪费了半天时间。
2.在 kernel/printk.c 中增加写文件函数fprintk() 。
这个使用实验指导书给出的即可。注意对于

需要进行修改。
若是不进行修改,则程序可进行,但是无法写入process.log,又一个不好好看指导书的教训。
3.在进程的状态改变时,向log文件中写入记录。
由于进程的状态会在它创建、调度和销毁的时候发生改变,所以需要修改这三个过程对应的内核文件fork.c 、sched.c 和 exit.c ,在其中控制进程状态改变的代码后面加上一段向log文件写入记录的代码。
3.1 修改fork.c
真正实现进程创建的函数是 copy_process(),它定义在 kernel/fork.c 中,以下的一段代码设置了指向结构体变量的指针p的一系列属性之后,把start_time置成了jiffies,即相当于完成了进程的创建,所以在这行代码之后加上一条写log的代码,就可以记录进程新建的时刻。
1 | p = (struct task_struct *) get_free_page(); |
修改这两处地方
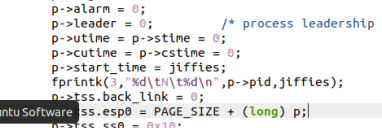

3.2 修改kernel/sched.c
以下的修改的原理类似,即在进程状态改变的时候添加fprintk()指令写log文件。
3.2.1修改schedule()
对原始代码新增fprintk后如下,实验中给出了提示:schedule() 找到的 next 进程是接下来要运行的进程(注意,一定要分析清楚 next 是什么)。如果 next 恰好是当前正处于运行态的进程,swith_to(next) 也会被调用。这种情况下相当于当前进程的状态没变。
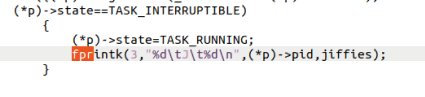
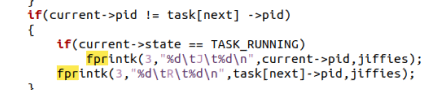
3.2.2修改sys_pause()
系统无事可做的时候,进程 0 会不停地调用 sys_pause(),以激活调度算法。此时它的状态可以是等待态,等待有其它可运行的进程;也可以叫运行态,因为它是唯一一个在 CPU 上运行的进程,只不过运行的效果是等待。

3.2.3修改sleep_on()
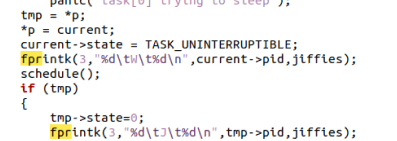
3.2.4修改interruptible_sleep_on()
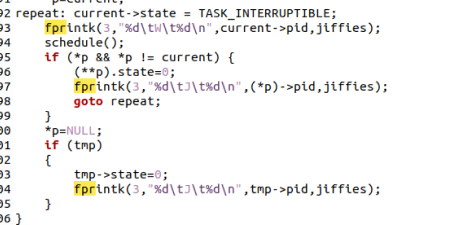
3.2.5修改wake_up()
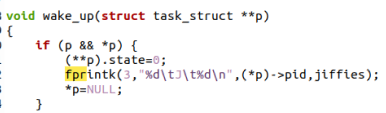
3.3修改kernel/exit.c
3.3.1修改do_exit
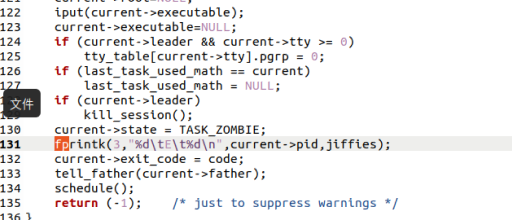
3.3.2修改sys_waitpid

4.最终编写一个process.c程序,用它创建多个进程来进行测试。
该文件的目的是创建几个进程用来测试,注意用到fork()和wait()两个函数。
fork()函数,简单说该函数的作用就是创建一个子进程,开辟一条与父进程平行的时间线,即创建了一个分叉路口。在调用fork的时候就产生这个分叉路口了,fork之前与之后的代码都会被分岔路口之后的父进程和子进程执行。
fork它在父进程和子进程里的返回值是不同的:父进程中返回子进程的ID,子进程中返回0(。 那么如果我想让一条语句在子进程中执行而不在父进程中执行,那么就可以判断fork()的返回值是不是等于0,如果等于0就执行这条语句。
wait()函数,当调用该函数时(如果没有参数),意思就是判断当前进程的子进程有没有结束,如果有任意一个子进程结束了,那么当前进程就可以结束了,否则就处于阻塞状态;如果当前进程已经没有子进程了,那么就不会发生什么事,不会阻塞,只是wait的返回值发生变化。也就是说,如果当前进程有三个子进程,如果我要让这三个子进程先结束,让当前进程最后结束,那么就连用三个wait(),才能确保当前进程在三个子进程都结束后再结束。
注:关于这部分知识可参考CSAPP,有详细介绍过。
1 | #include <stdio.h> |
5.测试
1 | sudo ./mount-hdc |
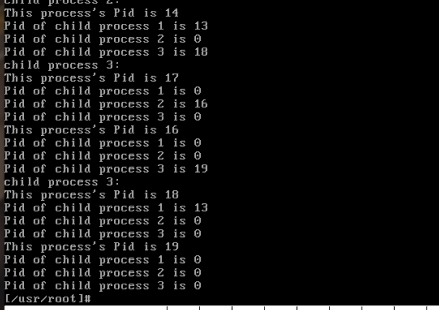
运行sync指令进行同步,将缓冲区信息加载到硬盘。然后关闭模拟器,再次挂载hdc后,进入查看hdc/var/process.log。
1 | sync |
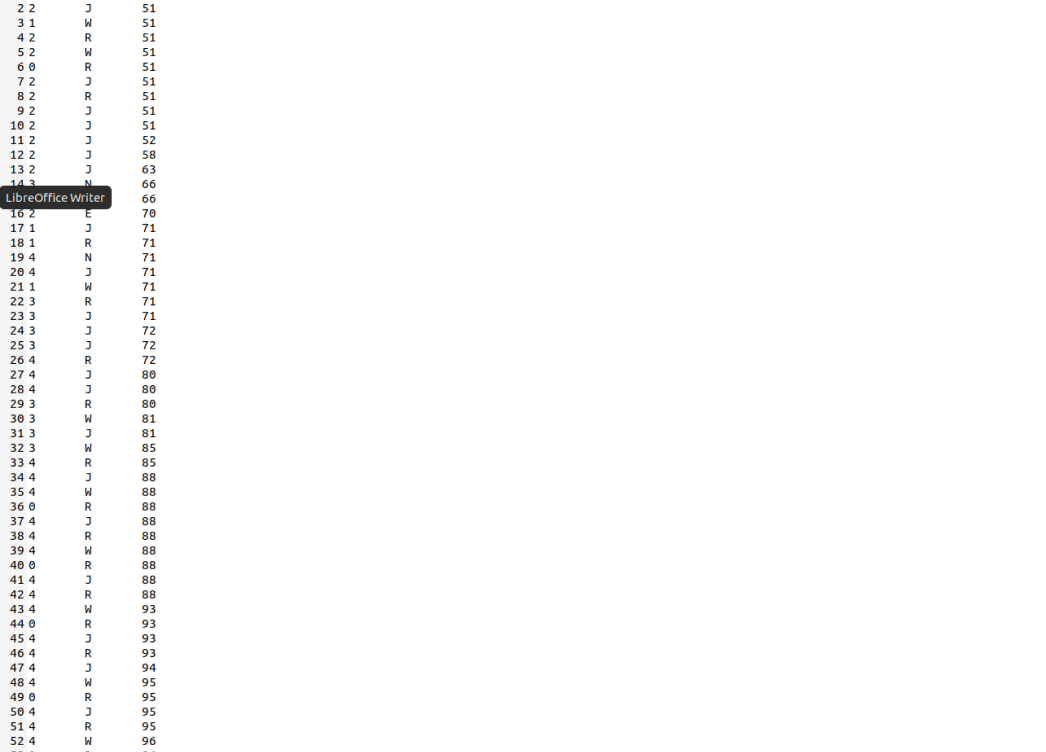
1 | cp ./hdc/var/process.log ./ |
注:由于修改了实验环境,所以从进程一开始打印,所以对应的stat_log.py也需要修改,主要修改如下

在这里额外补充进程1的新建和运行。
因为对于本次实验,我们是在进程1运行后才开始写入的,所以没有进程0与进程1的创建,而我们对应的py程序又会将其检测为一个error,报nonew的异常,所以需要手动补充。
修改时间片
nux0.11采用的调度算法是一种综合考虑进程优先级并能动态反馈调整时间片的轮转调度算法。 它为每个进程分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程;如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。
综合考虑进程优先级:一个进程在阻塞队列中停留的时间越长,它的优先级就越大,下次就会被分配更大的时间片。
进程之间的切换是需要时间的,如果时间片设定得太小的话,就会发生频繁的进程切换,因此会浪费大量时间在进程切换上,影响效率;如果时间片设定得足够大的话,就不会浪费时间在进程切换上,利用率会更高,但是用户交互性会受到影响,在这里老师上课讲的银行的例子就可以拿过来。
时间片的初始值是进程0的priority,是在linux-0.11/include/linux/sched.h的宏 INIT_TASK 中定义的,如下:我们只需要修改宏中的第三个值即可,该值即时间片的初始值
1 | #define INIT_TASK \ |
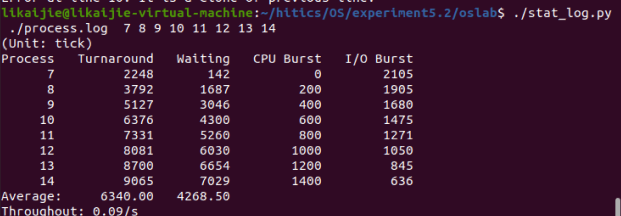
我修改了三个值,结果分别如下
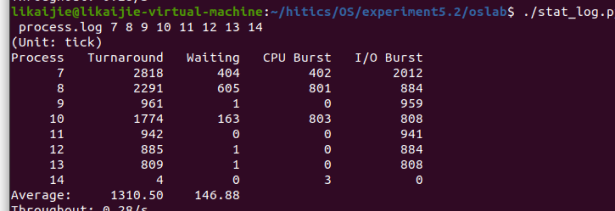
其中Average值发生了变化,throughout变化为小数点后发生的变化。
当时间片为10时:
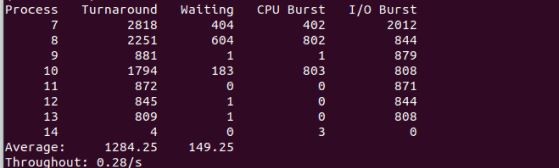
当时间片为15时:
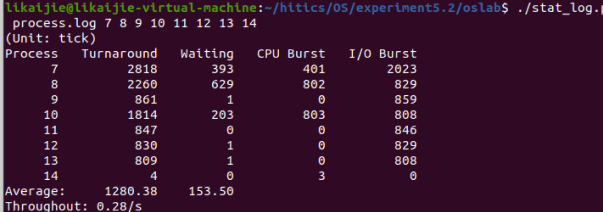
当时间片为20时:
问题回答
问题1:单进程编程和多进程编程的区别?
1 | 1.执行方式:单进程编程是一个进程从上到下顺序进行;多进程编程可以通过并发执行,即多个进程之间交替执行,如某一个进程正在I/O输入输出而不占用CPU时,可以让CPU去执行另外一个进程,这需要采取某种调度算法。 |
问题2:你是如何修改时间片的?仅针对样本程序建立的进程,在修改时间片前后, log 文件的统计结果(不包括Graphic)都是什么样?结合你的修改分析一下为什么会这样变化,或者为什么没变化?
1 | 将时间片变小,进程调度次数变多,系统会使得该进程等待时间变长。 |