凯恩帝报表管理系统
数据库部分
创建数据库
1 | --创建数据库School Classroom Management Information System-SCMIS |
系统部分
1 | --系统型号 |
驱动部分
1 | --驱动部分 |
选择件部分
1 | --选择件部分 |
电缆
1 | --系统电缆 |
插入一些基础值
1 | use KND |
创建约束
1 | use KND |
创建记录
1 | use KND |
1 | --创建数据库School Classroom Management Information System-SCMIS |
1 | --系统型号 |
1 | --驱动部分 |
1 | --选择件部分 |
1 | --系统电缆 |
1 | use KND |
1 | use KND |
1 | use KND |
近朱者赤近墨者黑,分类或者回归算法。
n_neighbors:找最近的n个邻居,然后根据n个邻居判断它为什么。在机器学习库中,默认为5.
weights:默认是uniform, 参数可以是uniform、distance, 也可以是用户自己定义的函数
leaf_size: 默认是30, 这个是构造的kd树和ball树的大小. 这个值的设置会影响树构建的速度和搜索速度, 同样也影响着存储树所需的内存大小. 需要根据问题的性质选择最优的大小
p : minkowski距离度量里的参数. p=2时是欧氏距离, p=1时是曼哈顿距离,对于任意p, 就是minkowski距离
注:欧式距离为两个点的实际距离;曼哈顿距离为出租车距离,即遵守正南正北、正东正西方向规则;马氏距离:概率论距离,即基于样本分布距离。



n_estimators:树的个数(学习器的个数),提高数值,提高模型准确率,但是训练时间变长

max_depth:树的最大深度


超参数介绍参考随机森林
kernel:核函数
C:惩罚参数
n_estimators:为弱学习器的数量‘
learning_rate:为弱学习器的权重缩减系数。
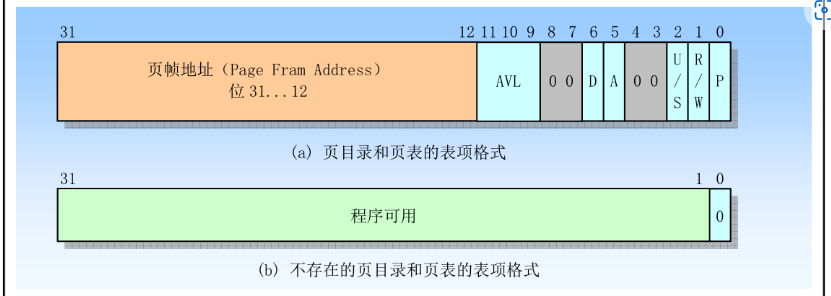
线性地址和物理地址之间的变换
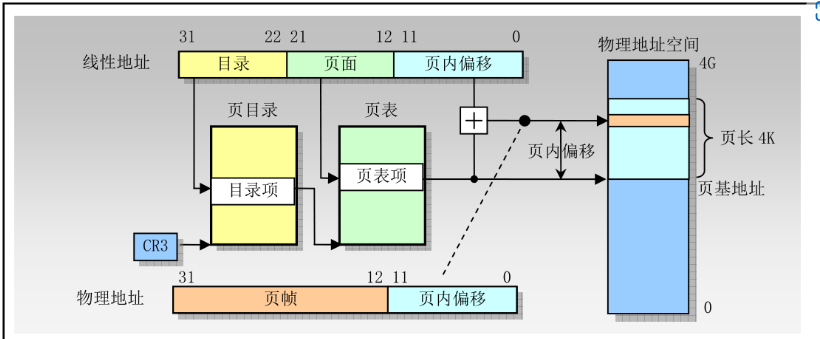
页目录和页表的表项格式
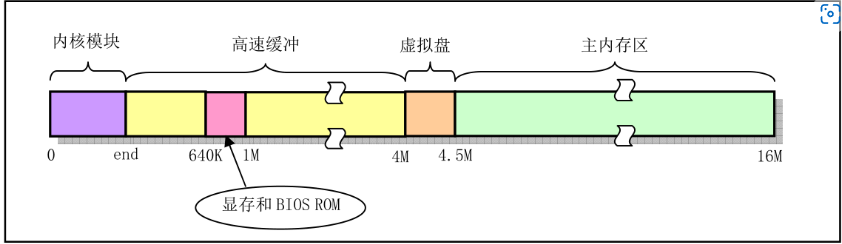
主内存区域
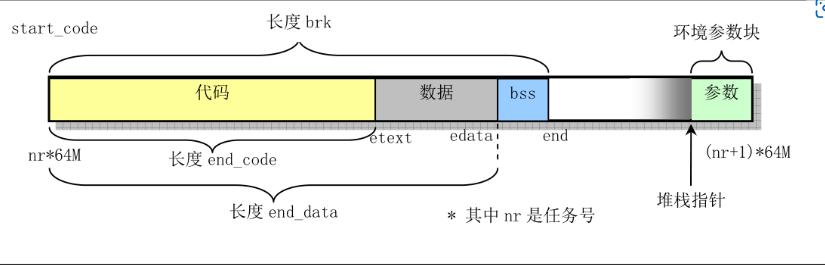
进程代码和数据在其逻辑地址空间中的分布
把debug_paging函数声明为全局变量,添加中断函数表。
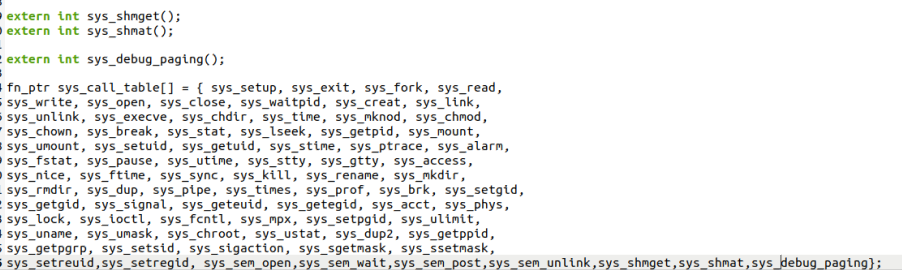
把对应的函数个数进行修改

需要在unistd.h 中修改,注意进行挂载。
运行 sudo ./mount-hdc 可以把虚拟机硬盘挂载在 oslab/hdc 目录下。
在 hdc/usr/include 目录下修改 unistd.h
将完成的文件放入linux-0.01/kernel 目录下


1 | 不是。可以充分利用碎片的内存空间,提高空间利用率。 |
Linux (x86-64) 是怎么处理分段的?1 | 不是。在64位模式下:处理器把CS/DS/ES/SS的段基都当作0,忽略与之关联的段描述符中的段基地址。因为在64位模式中,CPU可以访问所有可寻址的内存空间。x86工作在保护模式下时,分段单元将逻辑地址转换成线性地址,分页单元(MMU开启情况下)将线性地址转换成物理地址。当CPU启用了MMU,CPU核发出的地址将被MMU截获,从CPU到MMU的地址称为虚拟地址,而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将虚拟地址映射成物理地址,在x86_64上,处理器把CS/DS/ES/SS的段基都当作0,实际上摒弃了段式管理,不再使用。指令中使用的地址就是线性地址,当CPU开启MMU时,通过页式管理单元翻译成物理地址。 |
Bochs 调试工具跟踪 Linux 0.11 的地址翻译(地址映射)过程,了解 IA-32 和 Linux 0.11 的内存管理机制;Ubuntu 上编写多进程的生产者-消费者程序,用共享内存做缓冲区;Linux 0.11 增加共享内存功能,并将生产者-消费者程序移植到 Linux 0.11 。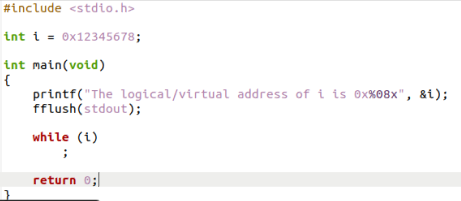
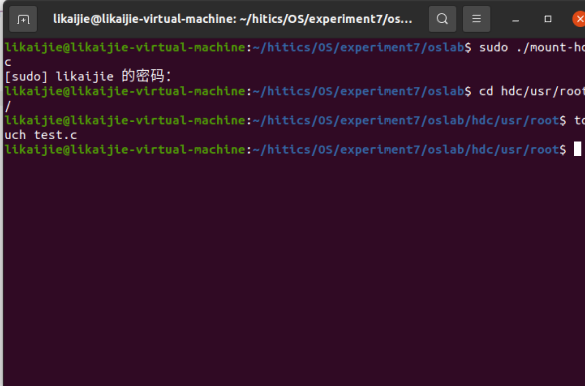
首先进入Linux-0.11目录内make编译系统,然后运行系统,编译运行test.c文件
1 | gcc -o test test.c |

此时会进入在test.c内的while死循环,然后ctrl+c暂停bochs。
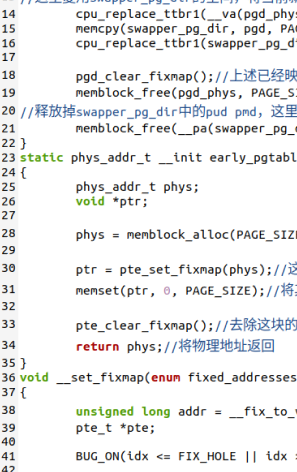
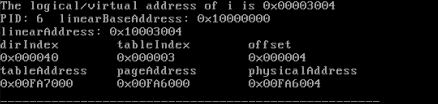
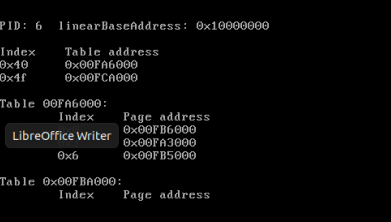
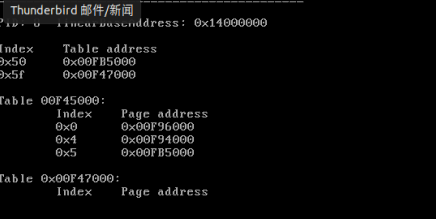
此时需要让Linux-0.11的test跳出死循环,所以需要找到逻辑地址ds:0X00003004对应的物理地址,将它的内容更改为0。
在终端中输入sreg,得到gdtr的基址值为0x00005cb8,ldtr为0x0068即0000 0000 0110 1000 b,可知索引为1101b即13,TI位为0,即GDT中的第13项为LDT的段描述符。
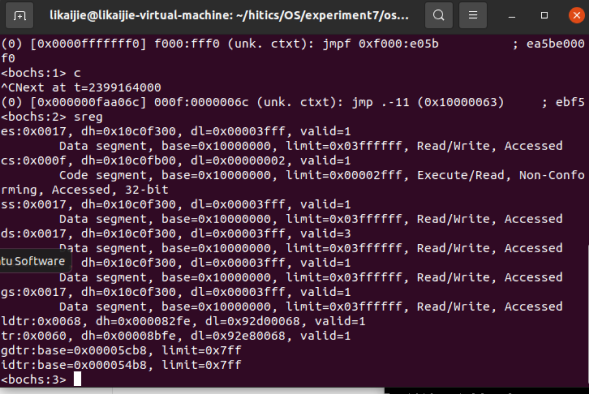
输入
1 | xp /2w 0x00005cb8+13*8 |

可以得到LDT的基址为0x00fe92d0
ds段选择子为0x0017 => 0000 0000 0001 0111 b,可知索引为10b即2,TI位为1,即LDT中的第2项为ds的段描述符
输入
1 | xp/2w 0x00fe92d0+2*8 |
得到ds段描述符
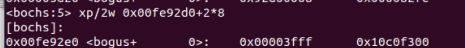
可以知道ds的基址为0x10000000,所以0x3004对应的线性地址为0x10000000+0x3004=0x10003004
输入
1 | xp /w 64*4 |
获取页目录项

表所在的物理页框号为0x00fa7,即页表在物理内存为0x00fa7000处,从该位置开始查找3号页表项
输入
1 | xp /w 0x00fa7000 + 3*4 |

线性地址0x10003004对应的物理页框号为0x00fa6,和页内偏移0x004接到一起,得到0x00fa6004,这就是变量i的物理地址
用
1 | xp /w 0x00fa6004 |
验证

修改物理地址,使其变量i为0
1 | setpmem 0x00fa6004 4 0 |

输入c,可以看到,会在bochs中顺利退出

在unistd.h中增加下面的代码
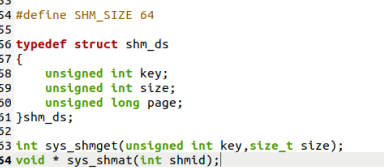
再添加系统调用

注意:要在挂载下再修改一次
增加函数声明
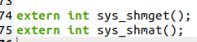

在system_call.s中把nr_system_calls改为78

在kernel目录下
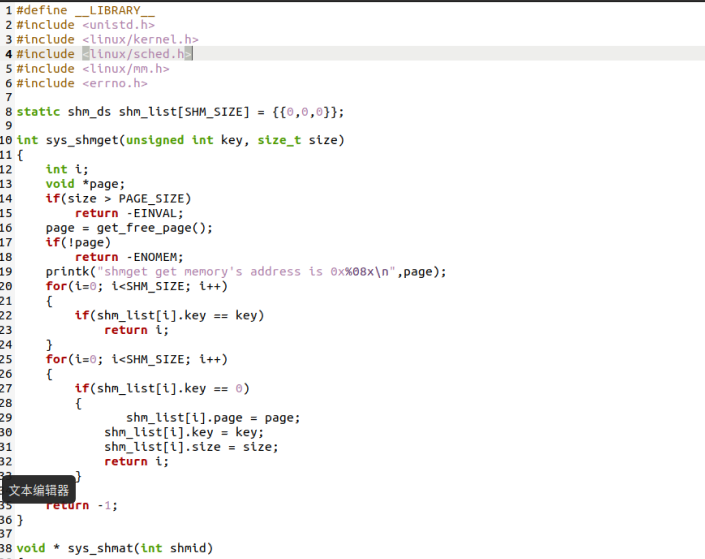
然后修改kernel下的Makefile

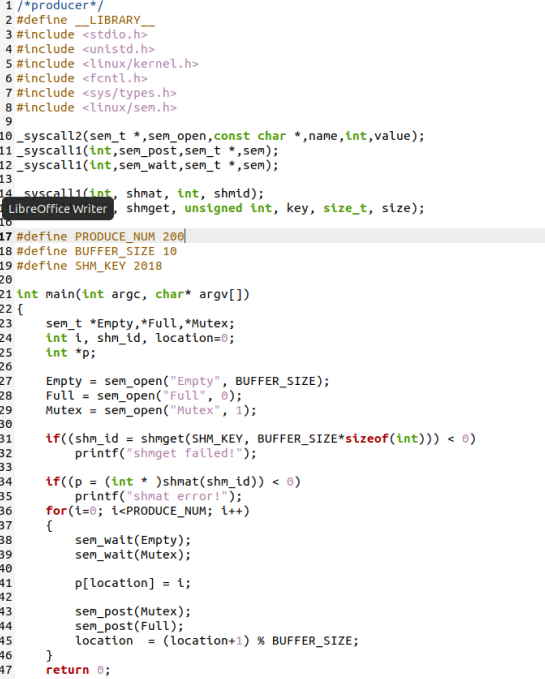
producer.c
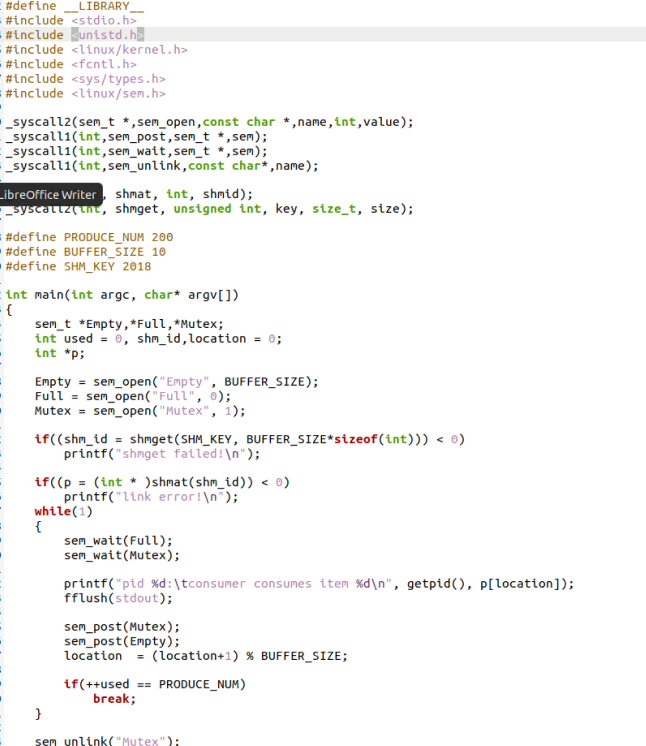
consumer.c
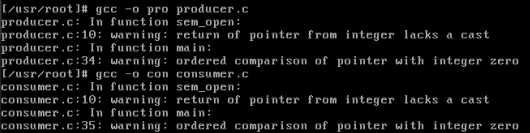
编译
1 | gcc -o pro producer.c |
输入
1 | pro > proOutput & |


输入
1 | sync |
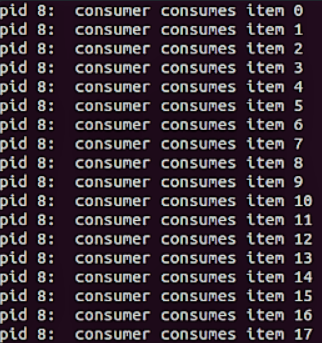
关闭linux-0.11回到ubunt终端,输入sudo less hdc/usr/root/conOutput查看结果如下
对于地址映射实验部分(第一部分),列出你认为最重要的几步(不超过四步),并给出你获得的实际数据。
1 | 输入命令u/7反汇编,查看变量i对应的逻辑地址 |
test.c退出后,如果马上再运行一次程序,并再进行地址跟踪,你会发现哪些异同?为什么?
1 | 再运行一次程序,等同于重来,变量i重新被赋非0值,所以仍然会死循环。 |
在消费者与生产者实现时,需要进行文件读写,实验指导书中提到,可通过借助标准C库函数来实现,或者直接通过对应的系统调用。
这里列出关于文件读写的三个函数说明
fseek()
C 库函数 int fseek(FILE *stream, long int offset, int whence) 设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。
声明如下
1 | int fseek(FILE *stream, long int offset, int whence) |
参数:
1 | stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。 |
| 常量 | 描述 |
|---|---|
| SEEK_SET | 文件的开头 |
| SEEK_CUR | 文件指针的当前位置 |
| SEEK_END | 文件的末尾 |
返回值:如果成功,则该函数返回0,否则返回非零值。
fread()
C 库函数 size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) 从给定流 stream 读取数据到 ptr 所指向的数组中。
声明如下
1 | size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) |
参数
1 | ptr -- 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针。 |
返回值:成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾。
fwrite()
C 库函数 size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) 把 ptr 所指向的数组中的数据写入到给定流 stream 中。
声明如下
1 | size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) |
参数
1 | ptr -- 这是指向要被写入的元素数组的指针。 |
返回值:如果成功,该函数返回一个 size_t 对象,表示元素的总数,该对象是一个整型数据类型。如果该数字与 nmemb 参数不同,则会显示一个错误。
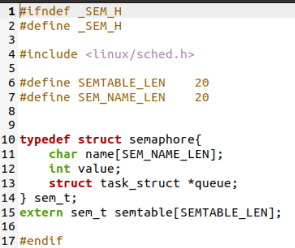
在linux-0.11/include/linux目录下新建sem.h,定义信号量的数据结构。
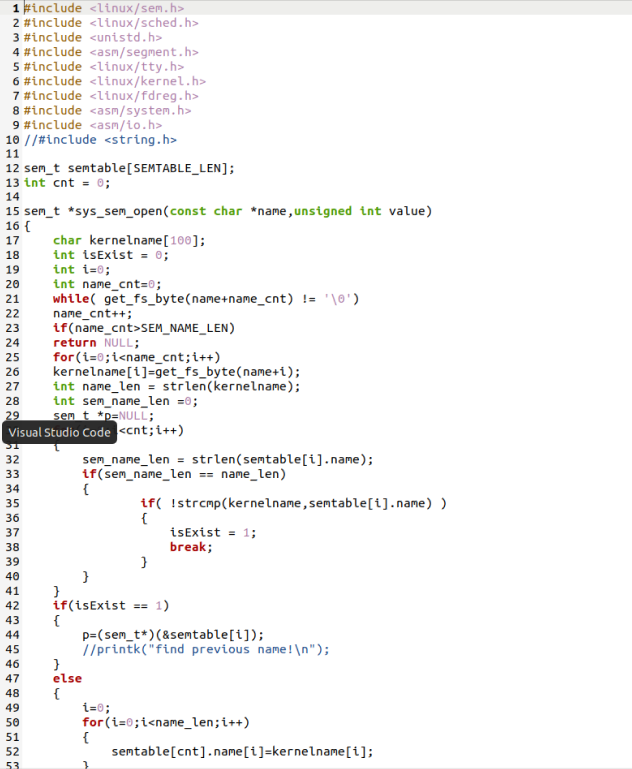
在linux-0.11/kernel目录下,新建实现信号量函数的源代码文件sem.c。
在其中增加对于信号量的系统调用编号,类似于之前的操作
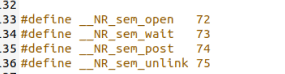
因为增加了四个sem系统调用函数,在system_call.s文件中找到nr_system_calls并将其值更改为76




在oslab根目录下执行
1 | sudo ./mount-hdc |
使用cp命令将unistd.h复制到usr/include下,将sem.h复制到usr/include/linux下
进行挂载,再,利用cp命令将其移动到usr/root目录下
运行linux-0.11之后,首先编译pc.c,使用命令
1 | gcc -o pc pc.c |
随后运行pc,使用命令
1 | ./pc > sem_output |
最终在虚拟环境内输入
1 | sync |
把修改的数据写入磁盘。
首先挂载hdc,然后进入usr/root目录并在终端内执行
1 | sudo less sem_output |
命令,可看到下图结果:
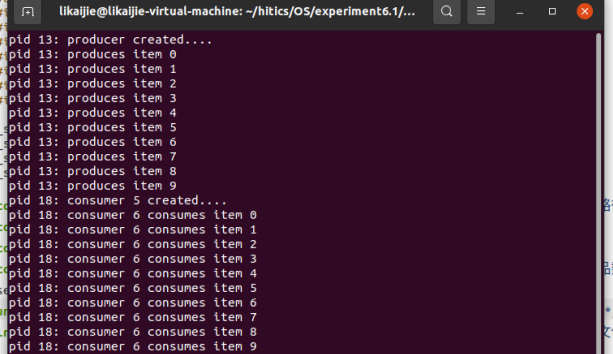
如果去掉所有与信号量有关的代码,编译运行程序之后可以发现输出的数字顺序完全混乱。
信号量不存在的情况下,进程之间无法同步或者协作,造成此种情况的有如下原因:
1 | - 一种情况是缓冲区满了,生产者还在写入数据,会造覆盖掉部分数据。 |
由于新改版的实验环境,打印进程 0 的相关内容会产生bug,可能是虚拟机或是其他原因引起的。 因此,后续所有的打印输出都是从进程 1 开始,所以对于init/main.c文件,将在进程1的关联代码后边补充打开log文件的代码。
修改如下:

如果要是按照之前版本进行修改,则进入linux0.11后,会一直在task[0]进行空转,血的教训,浪费了半天时间。
这个使用实验指导书给出的即可。注意对于

需要进行修改。
若是不进行修改,则程序可进行,但是无法写入process.log,又一个不好好看指导书的教训。
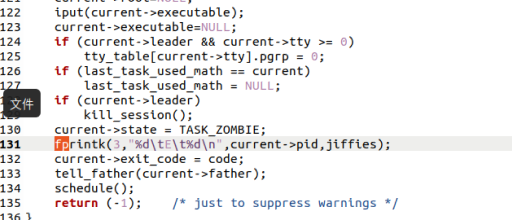
由于进程的状态会在它创建、调度和销毁的时候发生改变,所以需要修改这三个过程对应的内核文件fork.c 、sched.c 和 exit.c ,在其中控制进程状态改变的代码后面加上一段向log文件写入记录的代码。
真正实现进程创建的函数是 copy_process(),它定义在 kernel/fork.c 中,以下的一段代码设置了指向结构体变量的指针p的一系列属性之后,把start_time置成了jiffies,即相当于完成了进程的创建,所以在这行代码之后加上一条写log的代码,就可以记录进程新建的时刻。
1 | p = (struct task_struct *) get_free_page(); |
修改这两处地方
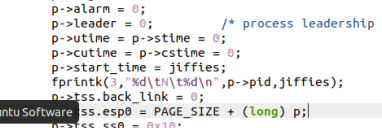

以下的修改的原理类似,即在进程状态改变的时候添加fprintk()指令写log文件。
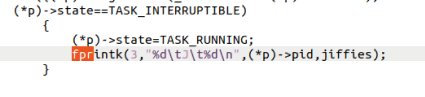
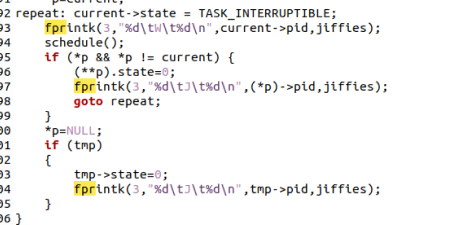
对原始代码新增fprintk后如下,实验中给出了提示:schedule() 找到的 next 进程是接下来要运行的进程(注意,一定要分析清楚 next 是什么)。如果 next 恰好是当前正处于运行态的进程,swith_to(next) 也会被调用。这种情况下相当于当前进程的状态没变。
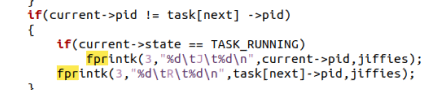
系统无事可做的时候,进程 0 会不停地调用 sys_pause(),以激活调度算法。此时它的状态可以是等待态,等待有其它可运行的进程;也可以叫运行态,因为它是唯一一个在 CPU 上运行的进程,只不过运行的效果是等待。

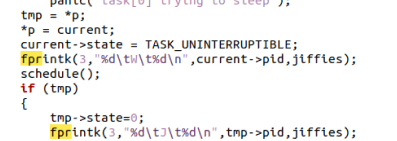
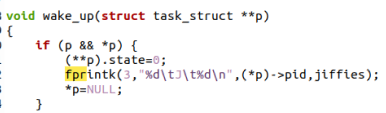

该文件的目的是创建几个进程用来测试,注意用到fork()和wait()两个函数。
fork()函数,简单说该函数的作用就是创建一个子进程,开辟一条与父进程平行的时间线,即创建了一个分叉路口。在调用fork的时候就产生这个分叉路口了,fork之前与之后的代码都会被分岔路口之后的父进程和子进程执行。
fork它在父进程和子进程里的返回值是不同的:父进程中返回子进程的ID,子进程中返回0(。 那么如果我想让一条语句在子进程中执行而不在父进程中执行,那么就可以判断fork()的返回值是不是等于0,如果等于0就执行这条语句。
wait()函数,当调用该函数时(如果没有参数),意思就是判断当前进程的子进程有没有结束,如果有任意一个子进程结束了,那么当前进程就可以结束了,否则就处于阻塞状态;如果当前进程已经没有子进程了,那么就不会发生什么事,不会阻塞,只是wait的返回值发生变化。也就是说,如果当前进程有三个子进程,如果我要让这三个子进程先结束,让当前进程最后结束,那么就连用三个wait(),才能确保当前进程在三个子进程都结束后再结束。
注:关于这部分知识可参考CSAPP,有详细介绍过。
1 | #include <stdio.h> |
1 | sudo ./mount-hdc |
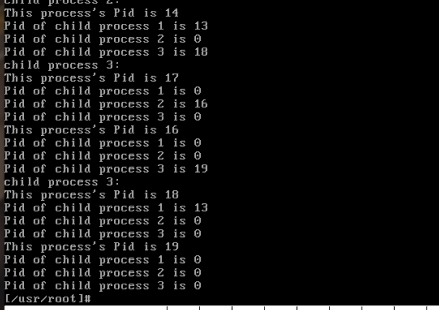
运行sync指令进行同步,将缓冲区信息加载到硬盘。然后关闭模拟器,再次挂载hdc后,进入查看hdc/var/process.log。
1 | sync |
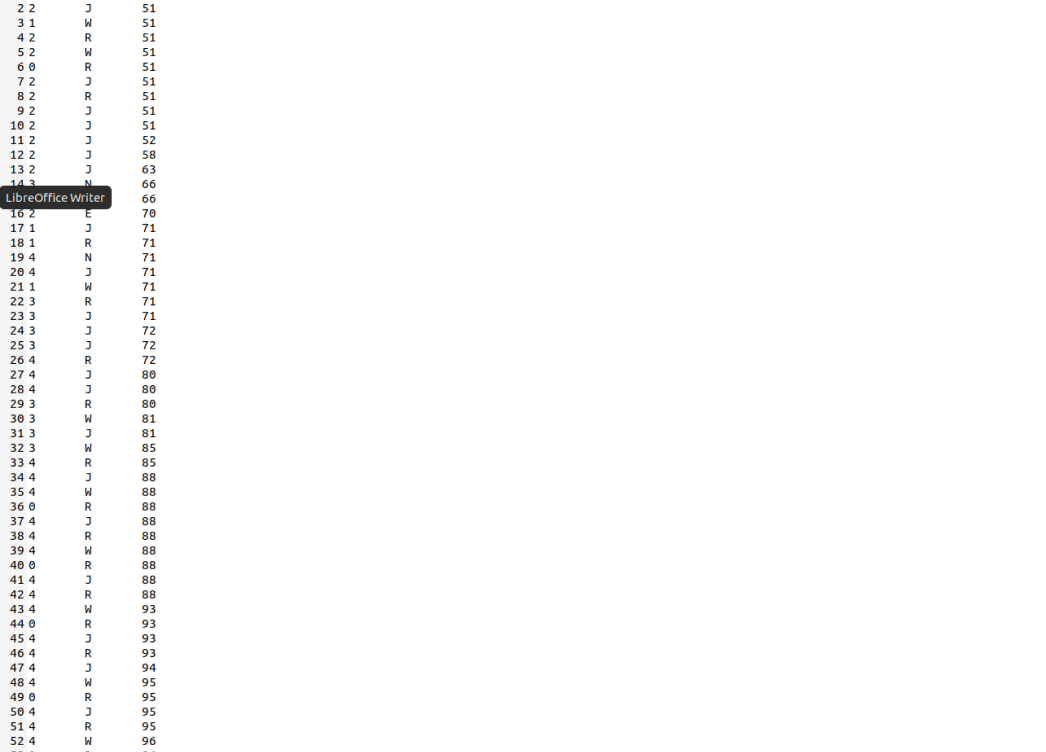
1 | cp ./hdc/var/process.log ./ |
注:由于修改了实验环境,所以从进程一开始打印,所以对应的stat_log.py也需要修改,主要修改如下

在这里额外补充进程1的新建和运行。
因为对于本次实验,我们是在进程1运行后才开始写入的,所以没有进程0与进程1的创建,而我们对应的py程序又会将其检测为一个error,报nonew的异常,所以需要手动补充。
修改时间片
nux0.11采用的调度算法是一种综合考虑进程优先级并能动态反馈调整时间片的轮转调度算法。 它为每个进程分配一个时间段,称作它的时间片,即该进程允许运行的时间。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程;如果进程在时间片结束前阻塞或结束,则CPU当即进行切换。调度程序所要做的就是维护一张就绪进程列表,当进程用完它的时间片后,它被移到队列的末尾。
综合考虑进程优先级:一个进程在阻塞队列中停留的时间越长,它的优先级就越大,下次就会被分配更大的时间片。
进程之间的切换是需要时间的,如果时间片设定得太小的话,就会发生频繁的进程切换,因此会浪费大量时间在进程切换上,影响效率;如果时间片设定得足够大的话,就不会浪费时间在进程切换上,利用率会更高,但是用户交互性会受到影响,在这里老师上课讲的银行的例子就可以拿过来。
时间片的初始值是进程0的priority,是在linux-0.11/include/linux/sched.h的宏 INIT_TASK 中定义的,如下:我们只需要修改宏中的第三个值即可,该值即时间片的初始值
1 | #define INIT_TASK \ |
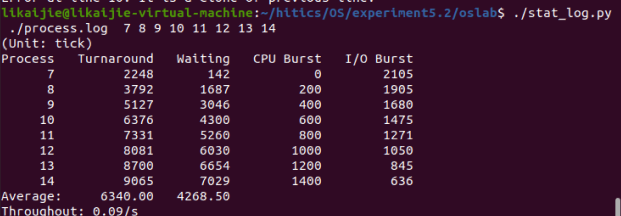
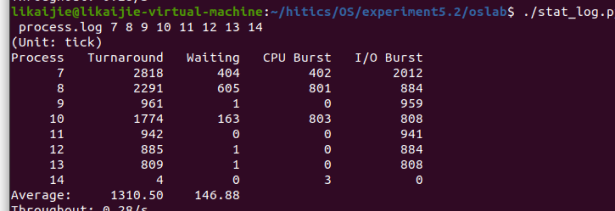
我修改了三个值,结果分别如下
其中Average值发生了变化,throughout变化为小数点后发生的变化。
当时间片为10时:
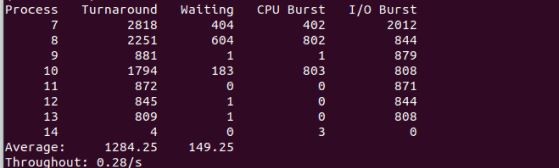
当时间片为15时:
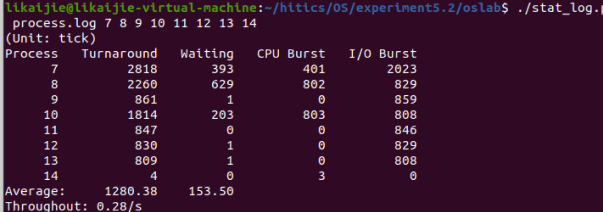
当时间片为20时:
问题1:单进程编程和多进程编程的区别?
1 | 1.执行方式:单进程编程是一个进程从上到下顺序进行;多进程编程可以通过并发执行,即多个进程之间交替执行,如某一个进程正在I/O输入输出而不占用CPU时,可以让CPU去执行另外一个进程,这需要采取某种调度算法。 |
问题2:你是如何修改时间片的?仅针对样本程序建立的进程,在修改时间片前后, log 文件的统计结果(不包括Graphic)都是什么样?结合你的修改分析一下为什么会这样变化,或者为什么没变化?
1 | 将时间片变小,进程调度次数变多,系统会使得该进程等待时间变长。 |
应用程序如何调用系统调用
在通常情况下,调用系统调用和调用一个普通的自定义函数在代码上并没有什么区别,但调用后发生的事情有很大不同。
调用自定义函数是通过 call 指令直接跳转到该函数的地址,继续运行。
而调用系统调用,是调用系统库中为该系统调用编写的一个接口函数,叫 API(Application Programming Interface)。API 并不能完成系统调用的真正功能,它要做的是去调用真正的系统调用,过程是:
把系统调用的编号存入 EAX;
把函数参数存入其它通用寄存器;
触发 0x80 号中断(int 0x80)。
linux-0.11 的 lib 目录下有一些已经实现的 API。Linus 编写它们的原因是在内核加载完毕后,会切换到用户模式下,做一些初始化工作,然后启动 shell。而用户模式下的很多工作需要依赖一些系统调用才能完成,因此在内核中实现了这些系统调用的 API。
为什么要有内核态和用户态两种状态?
因为有些操作很危险,比如清空内存,I/O等,不能随便一个程序就能进行这样的操作。所以区分出内核态与用户态,用户态可以执行一些不危险的操作,当需要执行危险操作时,需要通过系统调用等方法进入内核态执行。
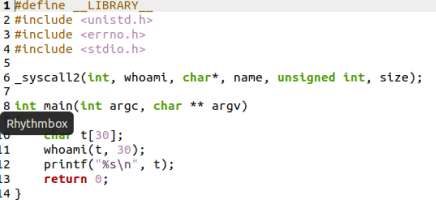
1.修改linux-0.11/include/linux/sys.h
需要把 iam() 与 whoami() 两个函数声明为全局变量,并添加到中断函数表中,当中断被调用的时候,先查找中断向量表,找到相应的函数名,调用其函数。
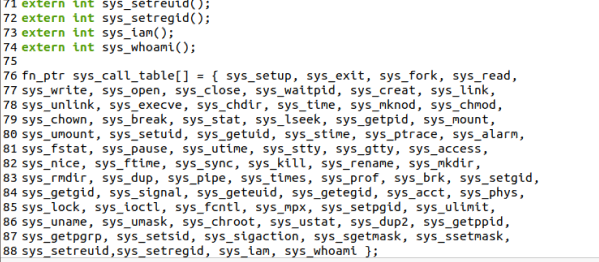
2.修改系统调用数
system_call.s 在 linux-0.11/kernel 中
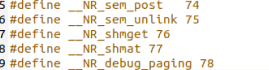
需要把nr_system_calls 由72改为 74 表示了中断函数的个数。

3.新增系统调用号
需要在unistd.h 中修改,但是实验后发现行不通,查阅后发现需要在linux系统中修改。
运行 sudo ./mount-hdc 可以把虚拟机硬盘挂载在 oslab/hdc 目录下。
在 hdc/usr/include 目录下修改 unistd.h
4.新增 who.c 文件,实现系统调用的函数
将完成的who.c文件放入linux-0.01/kernel 目录下


5.修改makefile
共有两处


6.新增 iam.c 和 whoami.c 文件以测试系统调用是否添加成功
iam.c
whoami.c
同理需要在linux0.11下编译
1 | sudo ./mount-hdc |
然后./run
7.编译 iam.c 跟 whoami.c
1 | gcc -o iam iam.c |
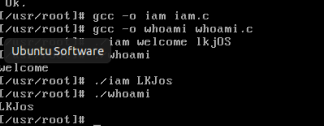
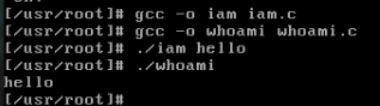
以及两个测试结果
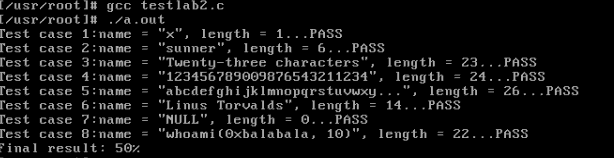
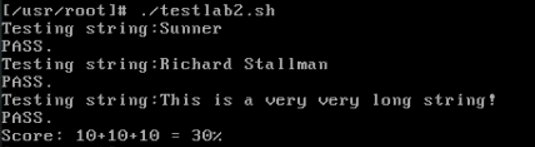
一、
Linux 0.11 现在的机制看,它的系统调用最多能传递几个参数?1 | Linux-0.11的系统调用通过寄存器ebx、ecx、edx传递参数,最多能传递3个参数。 |
二、
1 | 1.增加传参所用的寄存器 |
三、
Linux 0.11 添加一个系统调用 foo() 的步骤。1 | 1.在include/unistd.h中定义宏__NR_foo,并添加供用户调用的函数声明void foo(); |
记录一个只有自己遇到的问题,当我对于Linux0.11文件进行make时,发现会报错,具体错误如下,

当我调试后发现,问题出自linux/kernel/chr_drv处
当我用一个新的该文件,只在chr_drv下make时,会出现
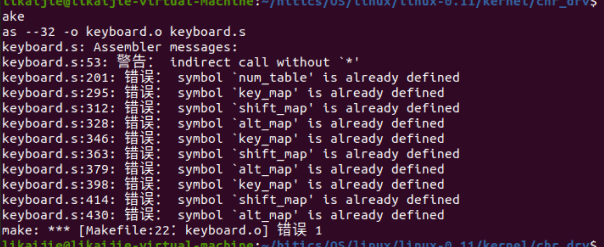
于是我make clean,再进行make,会出现下面的错误make

这两个问题分别对应于上面提到的那两个问题。
目前我没有找出这个问题的原因,我所采用的解决办法是,在其他机子上先对chr_drv文件进行编译,然后进行替换,则可以解决问题。困惑…
对的要求再复习一次
域再看一下,函数依赖再看一下,关系模式分解
1-3部分:选择,填空,查询 30
4-6部分:选择,填空,证明,设计 35
7-12部分:选择,填空,算法,分析 35


数据库:有组织的、共享的、持久存储的数据集合。
数据库管理系统:
数据库用户:
数据库系统:由数据库、数据库管理系统、应用程序和数据库用户在一起构成的系统。
数据库语言:数据定义语言;数据操作语言
数据模型:
数据库模式:
数据库实例:
数据库三层模式结构:数据库模式通常分三个层次定义,从低到高分别是:内模式/存储模式;概念模式;外模式/视图
内模式/存储模式:描述数据库的物理存储结构和存取方式;数据库只有一个内模式;定义内模式时通常使用物理数据模型提供的概念
概念模式:为全体数据库用户描述整个数据库的结构和约束;数据库只有一个概念模式;定义概念模式时使用实现数据模型提供的概念
外模式/视图:从不同类别用户的视角描述数据库结构;可以有多个外模式;定义外模式时也可以使用实现数据模型提供的概念
数据独立性:逻辑数据独立性;物理数据独立性

超键:可以唯一标识每个元组的属性。
候选键:任意真子集都不是超键的超键。即极小的超键。
域:
主属性:候选键中的属性。
完整性约束的类型:实体完整性、参照完整性、用户定义完整性。
实体完整性约束规则
1 | 主键值唯一且非空。 |
参照完整性约束
1 | 对于外键的约束,外键值为空或不为空则必须在S存在。 |
用户定义完整性约束
1 | 根据需求定义。 |
投影
并、差、交
重命名
$\theta$连接
等值连接:连接条件仅涉及相等比较的连接称作等值连接。
除
分组操作




注意:空值判断,应用 is null,不可以用 =或者!=
查询结果排序
聚集查询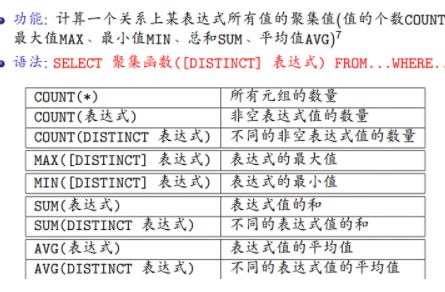
注:聚集函数不能出现在where子句中
分组查询

连接

使用exists关键字进行查询的时候,首先,我们先查询的不是子查询的内容,而是查我们的主查询的表,然后,根据表的每一条记录,依次去判断where后面的条件是否成立。
in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。









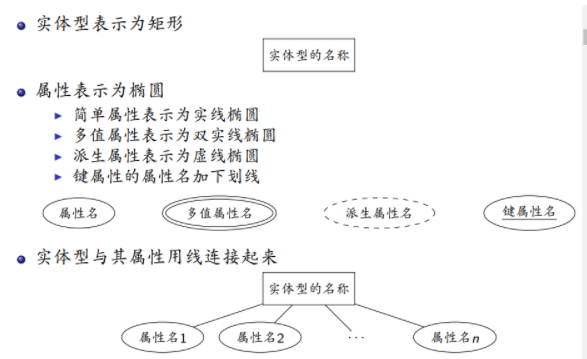
实体:数据库中表示的现实世界中的具体对象或事物。
属性:用于刻画实体的特性。
属性的类型
1 | 简单属性 |

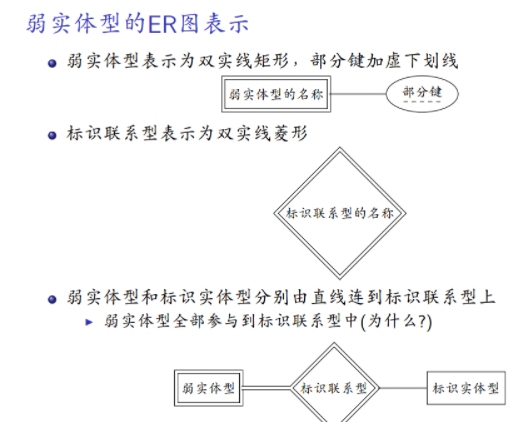
弱实体型:没有键属性的实体型。
标识实体型、属主实体型:由于弱实体型没有键属性,需要依赖于其他实体型进行区分。
标识联系型:弱实体型与其标识实体型通过标识联系型关联。
部分键:用于区分和同一标识实体相关联的弱实体的属性集合。
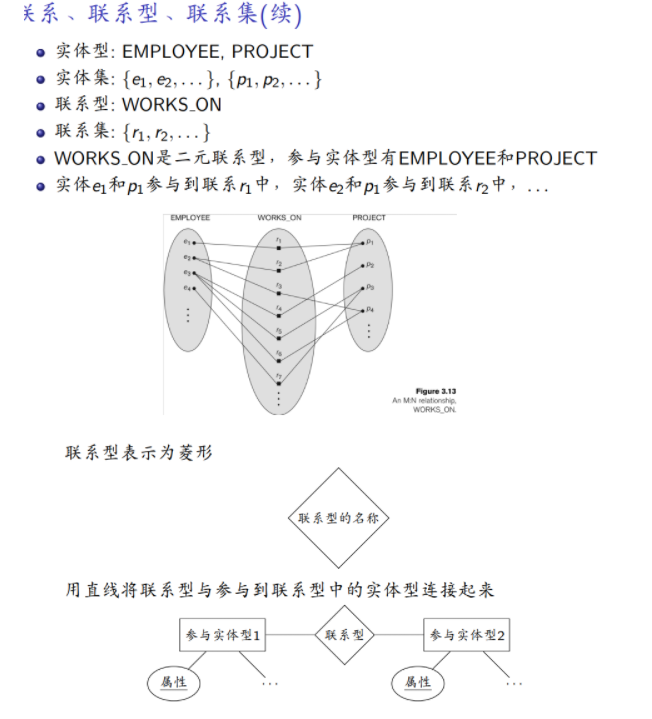
联系:一个联系表示多个实体之间有意义的关联关系。
联系型:同一类联系共同具有的类型。
联系型的度:参与到一个联系型中的实体型的个数。
联系集:数据库中当前存储的联系型的实例的集合。
基数比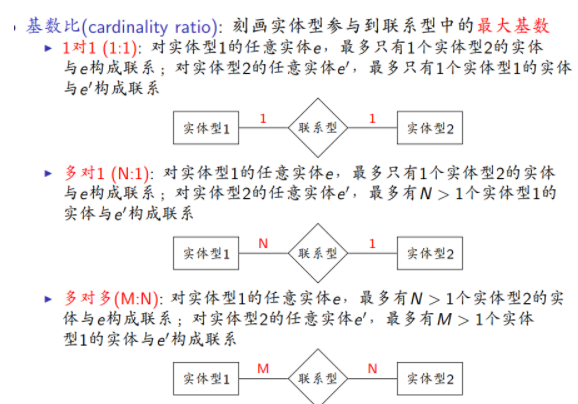
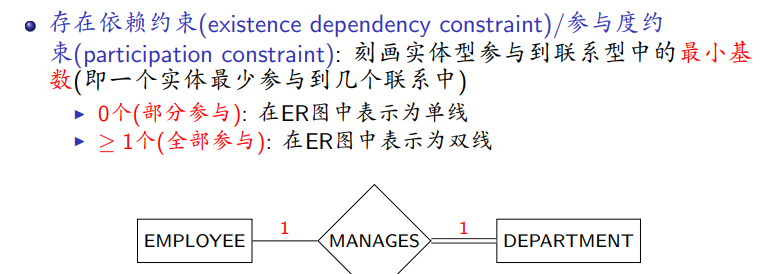
参与度
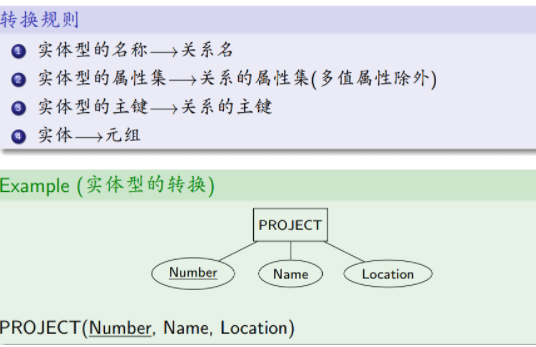
实体型的转换
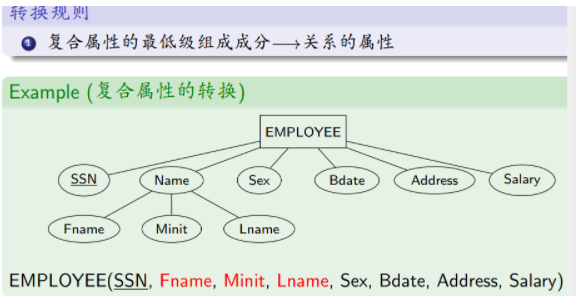
复合属性的转换
多值属性的转换

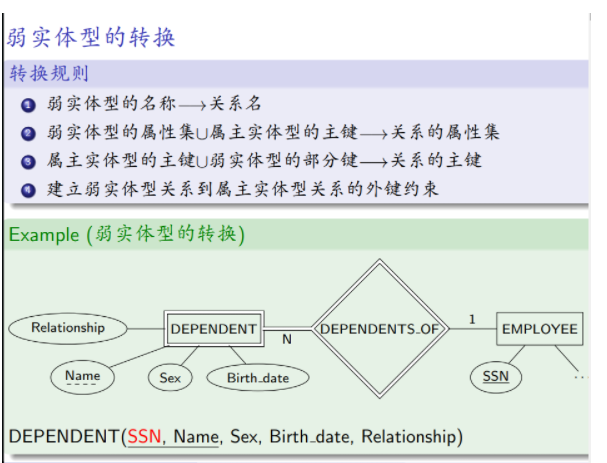
弱实体型转换
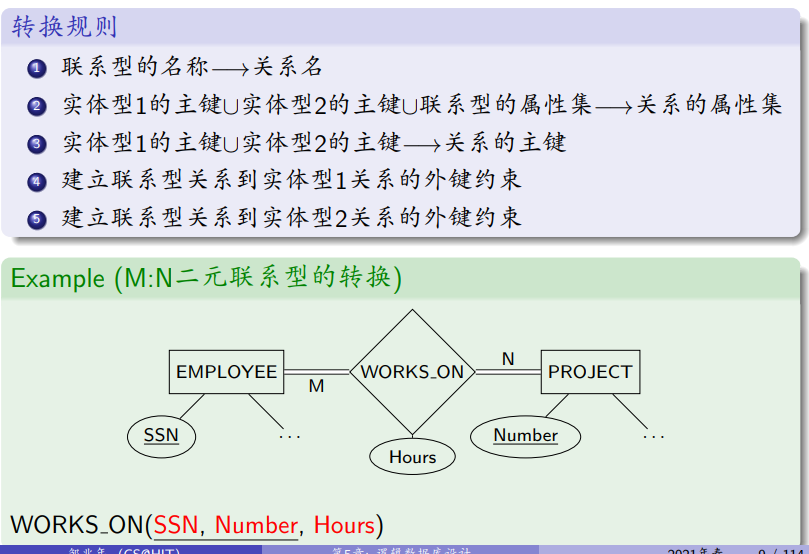
M:N二元联系型的转换
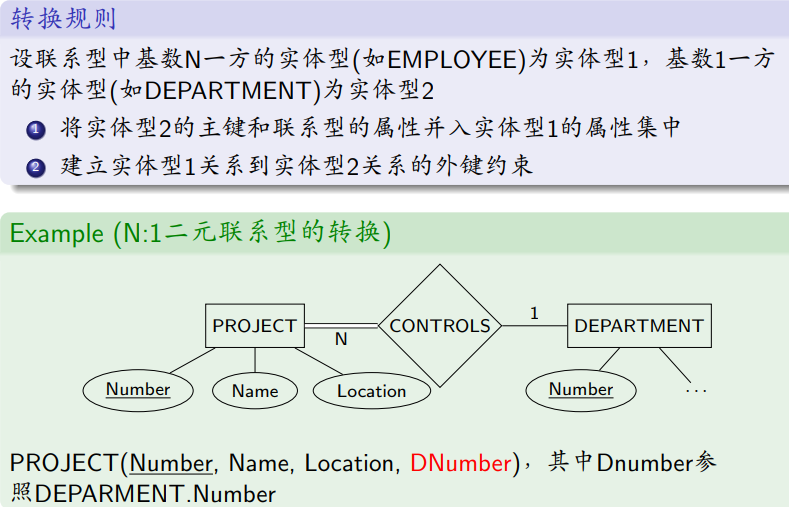
N:1二元联系型的转换
1:1二元联系型的转换
与N:1相同
定义

平凡函数依赖
完全函数依赖
部分函数依赖
传递函数依赖
逻辑蕴含

属性集闭包
等价函数依赖集

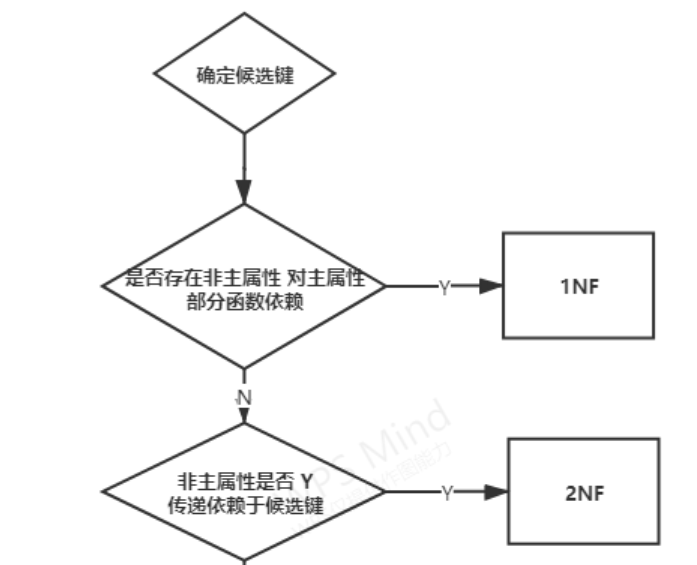
若关系模式R的每个属性都是不可分的,则称R为第一范式关系模式。
问题原因:非主属性部分函数依赖于候选键
第二范式

问题原因:非主属性传递函数依赖于候选键
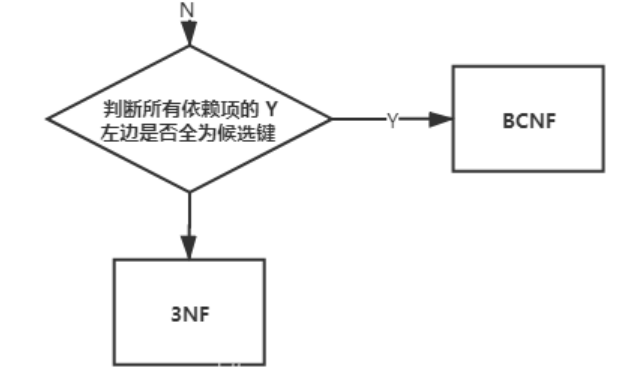
第三范式

问题原因:主属性部分依赖于候选键
BCNF

消除主属性间的传递依赖。
判断方法
1 | https://blog.csdn.net/weixin_43865875/article/details/115659734 |
分解准则1:无损连接性

分解准则2:函数依赖保持性

无损连接性判定

BCNF分解算法

3NF分解算法

根据数据文件中的元组是否按索引键值排序,分为聚簇索引与非聚簇索引。
聚簇索引
文件中的元组按索引键排序的,则索引为聚簇索引。
1 | 聚簇索引的索引键通常为关系主键; |
非聚簇索引
文件中的元组不按索引键排序的,则索引为非聚簇索引。
1 | 一个关系上可以有多个非聚簇索引 |
根据索引键是否为关系的主键,可将有序索引分为两类:主索引,二级索引
主索引
1 | 索引键为主键;一个关系只有一个 |
二级索引
1 | 索引键不是主键: |
根据关系中每个元组在索引中是否都有一个对应索引项,可将有序索引分为两类:稠密索引、稀疏索引






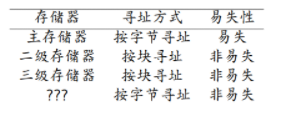
按CPU访问存储介质的方式,可将存储器分为三类。
1 | 主存储器 |
主存
1 | 包括:寄存器、高速缓存、内存 |
二级存储器
1 | 包括:磁盘/机械硬盘、闪存/固态硬盘 |
三级存储器
1 | 包括:磁带、光盘、网络存储 |
按存储介质的易失性/持久性,可分为
1 | 易失性存储器:计算机重启后,易失性存储器的数据会丢失 |
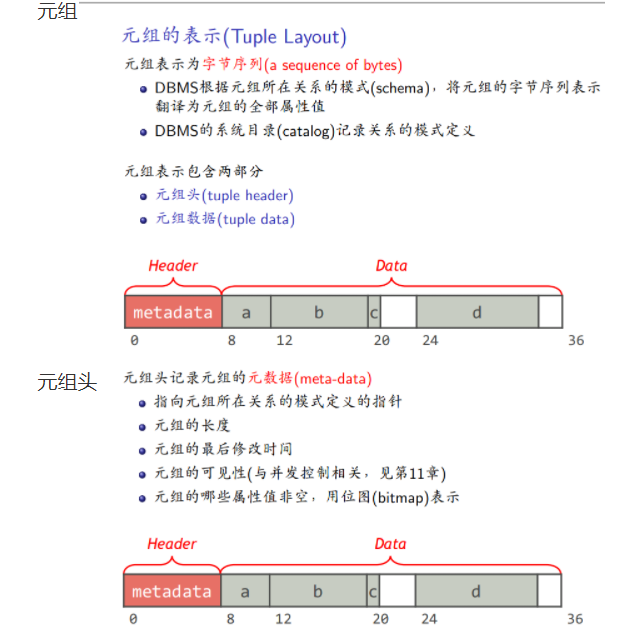
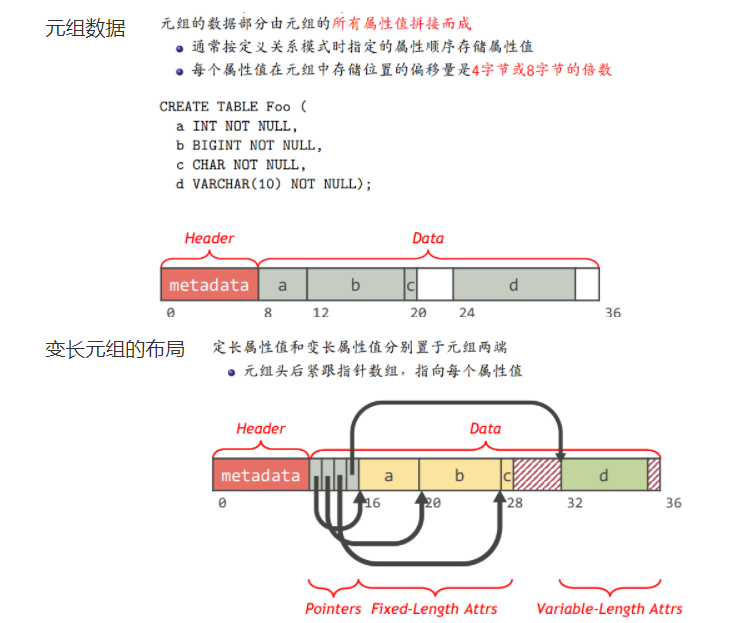
元组表示
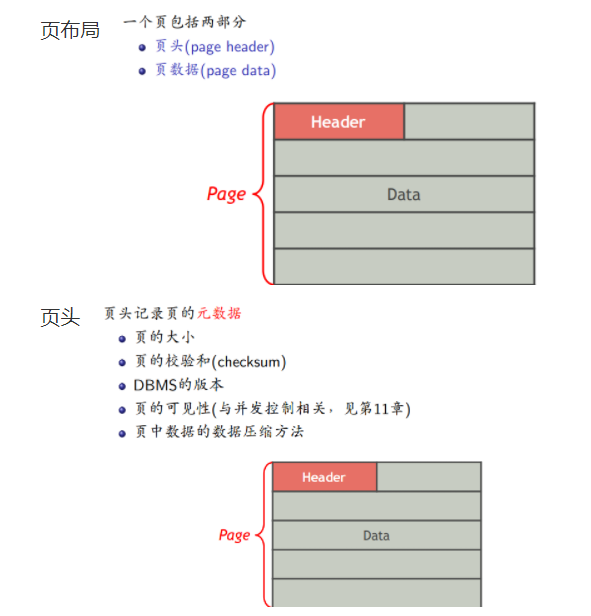
页布局
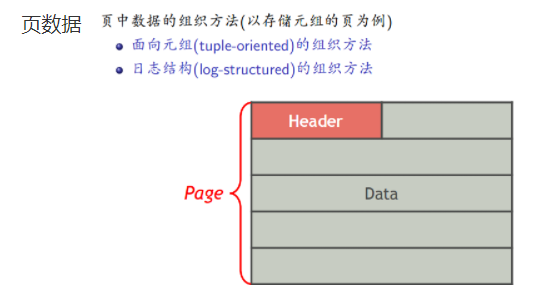
其余和原本内容一致,查看DBMS的文档。
可扩展哈希表
线性哈希表
B+树


句柄:句型的最左直接短语
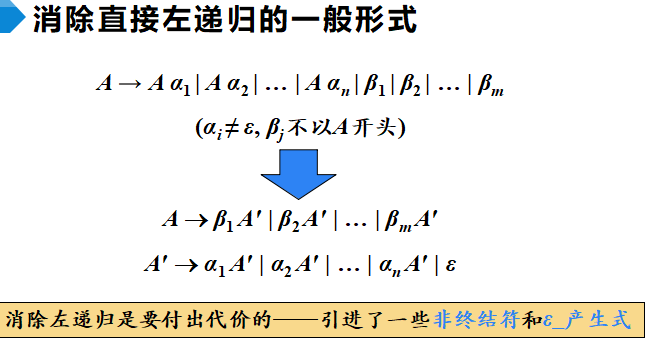
1 | 当且仅当G的任意两个具有相同左部的产生式A → α | β 满足下面的条件: |
1 | 关系:LR(0)<SLR(1)<LALR(1)<LR(1) |
1.判断LR(0)文法:
看项目中是否有归约-归约和移进-归约冲突。
如果无冲突则是LR(0)文法(如果是LR(0)文法则四种都是);如果有冲突则不是LR(0)文法。(就要向下判断)
2.判断SLR(1)文法:
a:DFA中存在冲突项目(归约-归约,归约-移进)
b:{a1,a2,…,an},FOLLOW(B1),FOLLOW(B2)两两互不相交,(交集=空集)时是SLR(1)项目。
【也就是说,同时满足两个条件才是SLR(1)文法】
若不是再向下判断。
3.判断LR(1)文法:
构造带向前搜索符的DFA,无归约-归约冲突则是LR(1)文法。
【此处意思是如果有向前搜索符还有冲突的话就不是LR(1)文法,就要再向下判断】
4.判断LALR(1)文法:
合并同心集后无(归约-归约)冲突(在之前的基础上)
(核相同,向前搜索符不同)
(B->a,a
B->a,a|b
同心集)
LR即指LR(1)

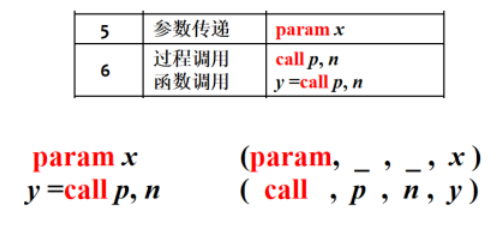
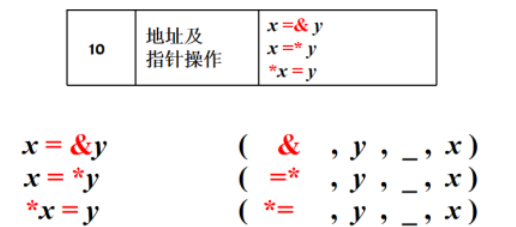
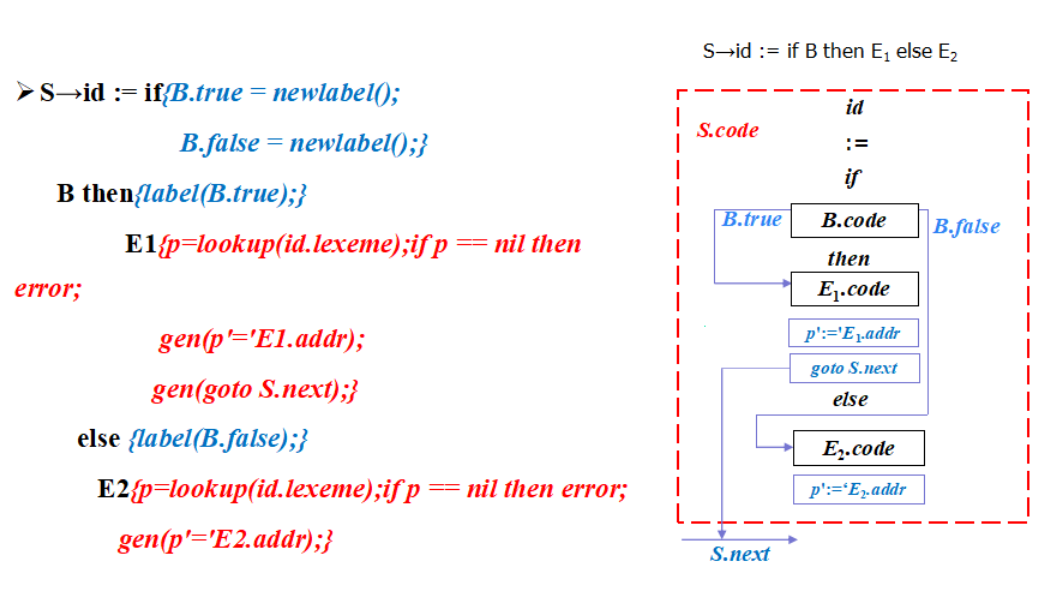
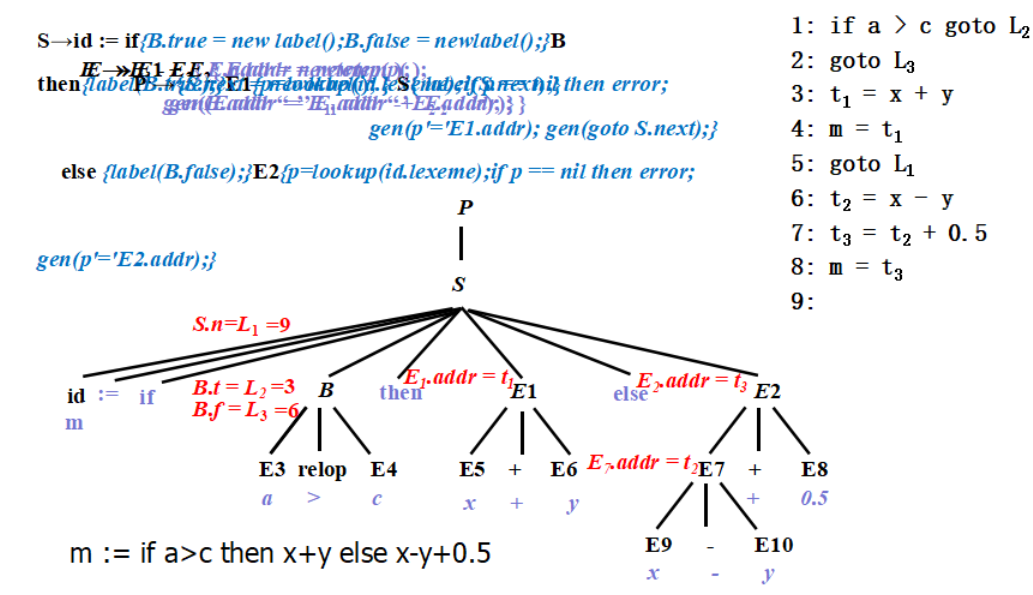
赋值语句的翻译
1 | newtemp( ):生成一个新的临时变量t,返回t的地址 |
数组引用的翻译
1 | L的综合属性 |
控制语句的翻译
1 | 继承属性 |
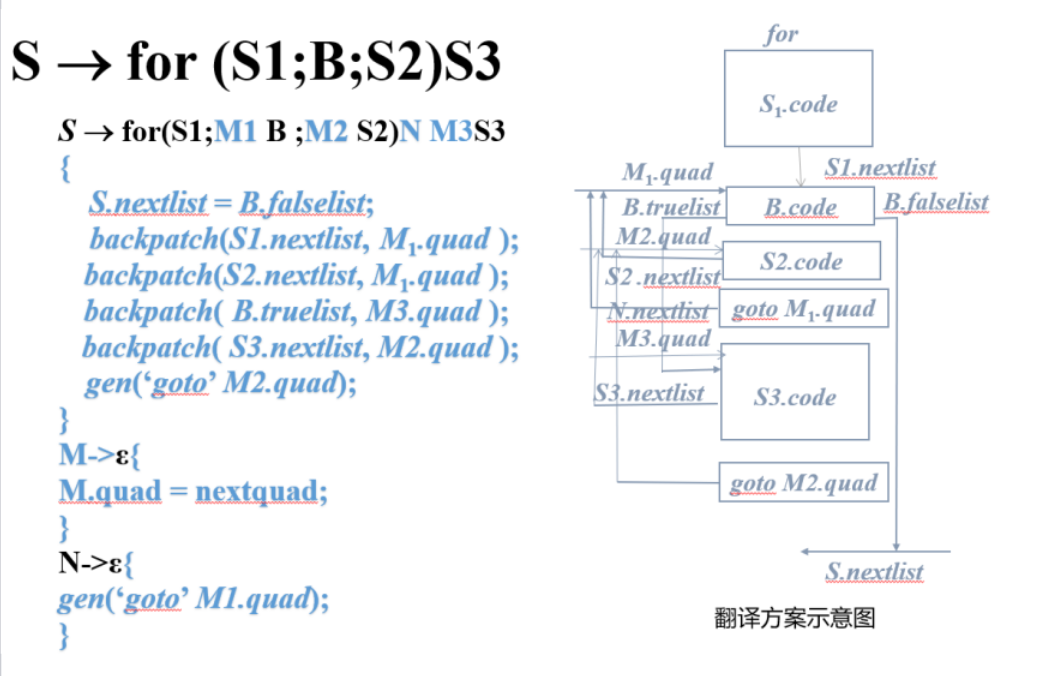
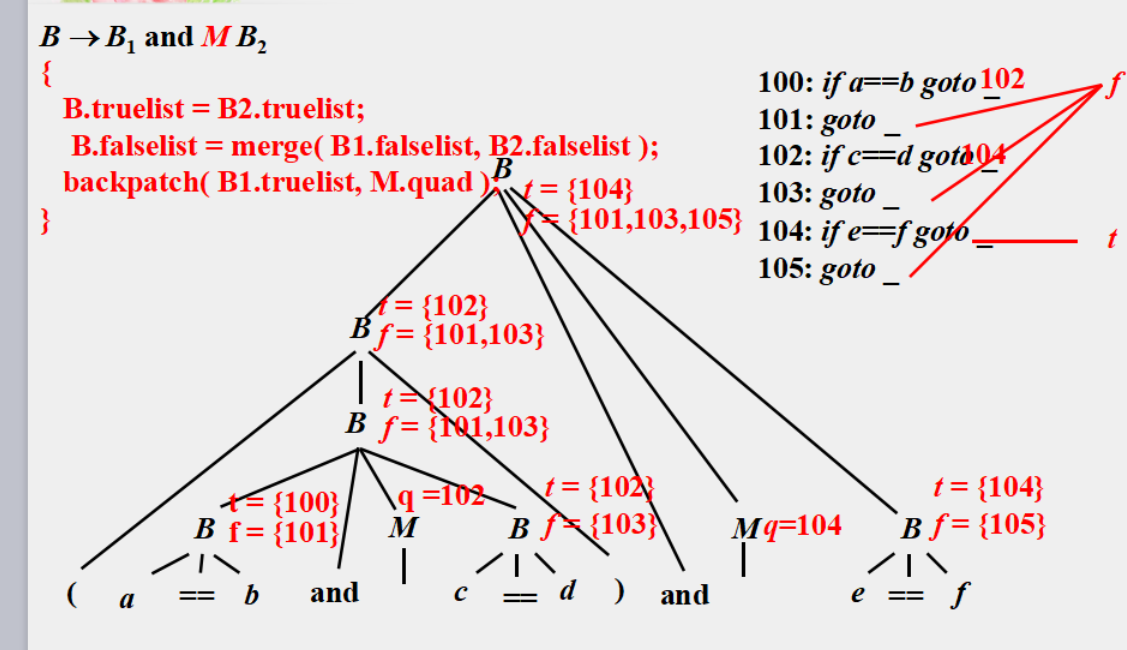
回填
非终结符B的综合属性
1 | B.truelist:指向一个包含跳转指令的列表,这些指令最终获得的目标标号就是当B为真时控制流应该转向的指令的标号 |
函数
1 | makelist( i ) |
1 | nextquad:即将生成的下一条指令的标号 |
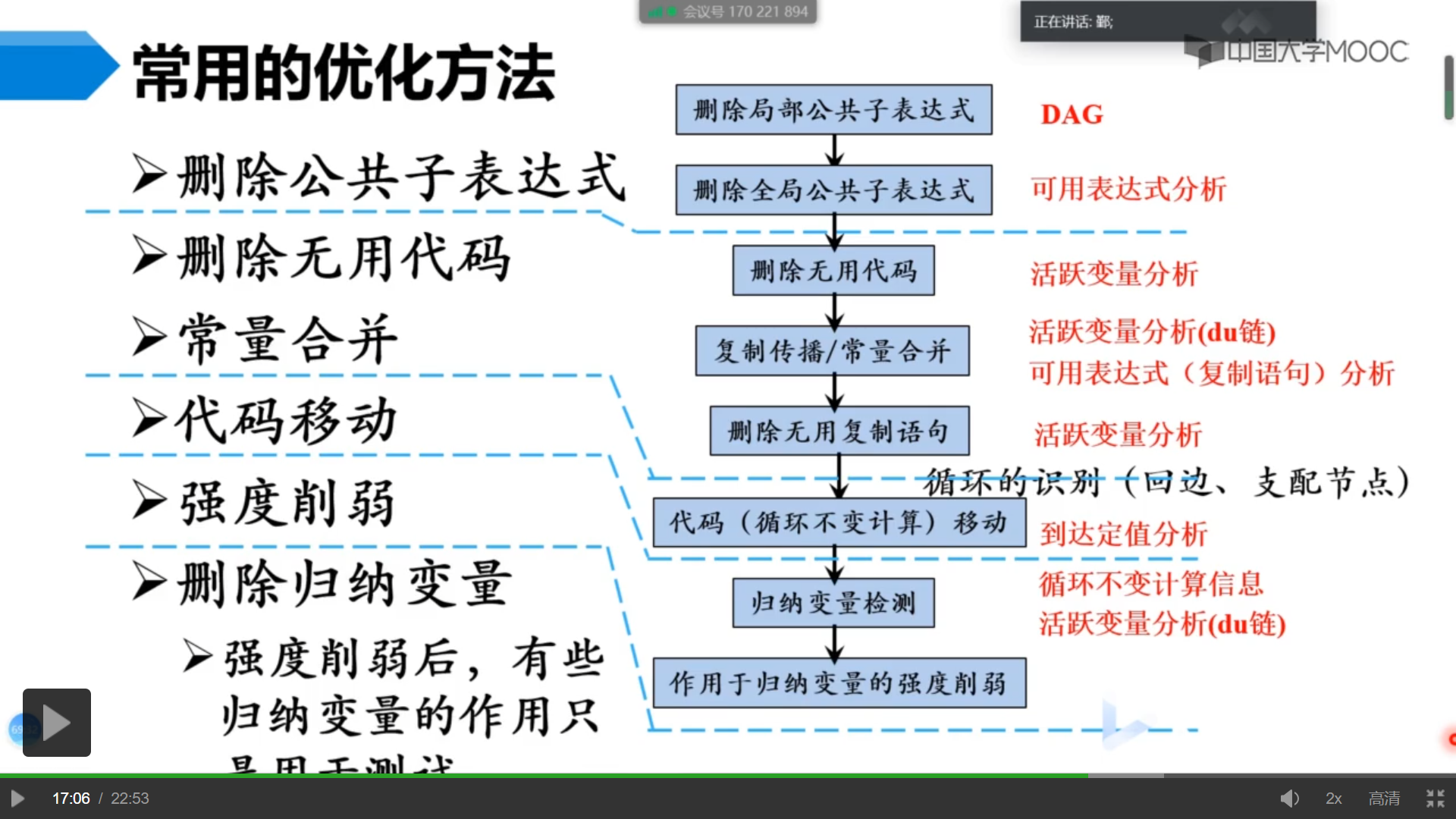
词法分析阶段可检测错误的类型:
1 | 单词拼写错误 |
最左规约称为规范规约,而最右推导相应的称为规范推导。
LL错误恢复:恐慌模式
LR错误恢复:恐慌模式错误恢复;短语层次错误恢复
这两种情况下,SDT可在语法分析过程中实现
1 | 基本文法可以使用LR分析技术,且SDD是S属性的 |
给定一个以LL文法为基础的L-SDD,可以修改这个文法,并在LR语法分析过程中计算这个新文法之上的SDD
1 | 给定一个以LL文法为基础的L-属性定义,可以修改这个文法,并在LR语法分析过程中计算这个新文法之上的SDD |

1 | 分析每一个非终结符之前 |

顺序分配法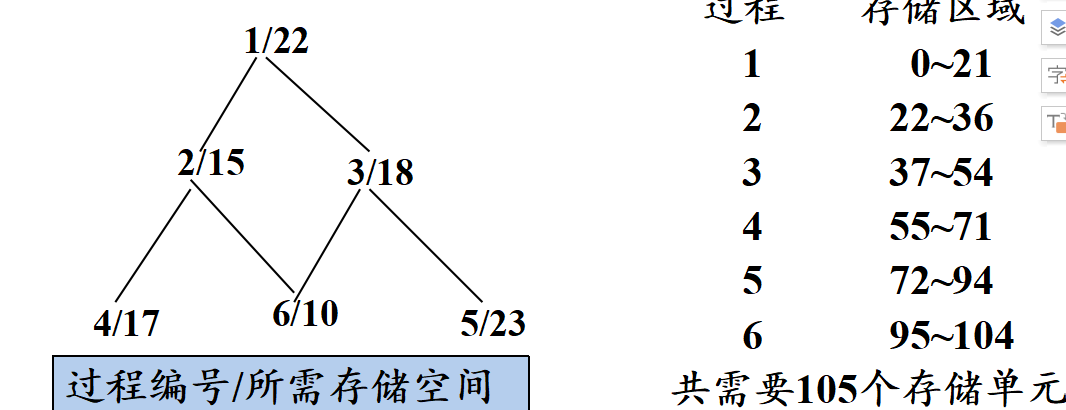
层次分配法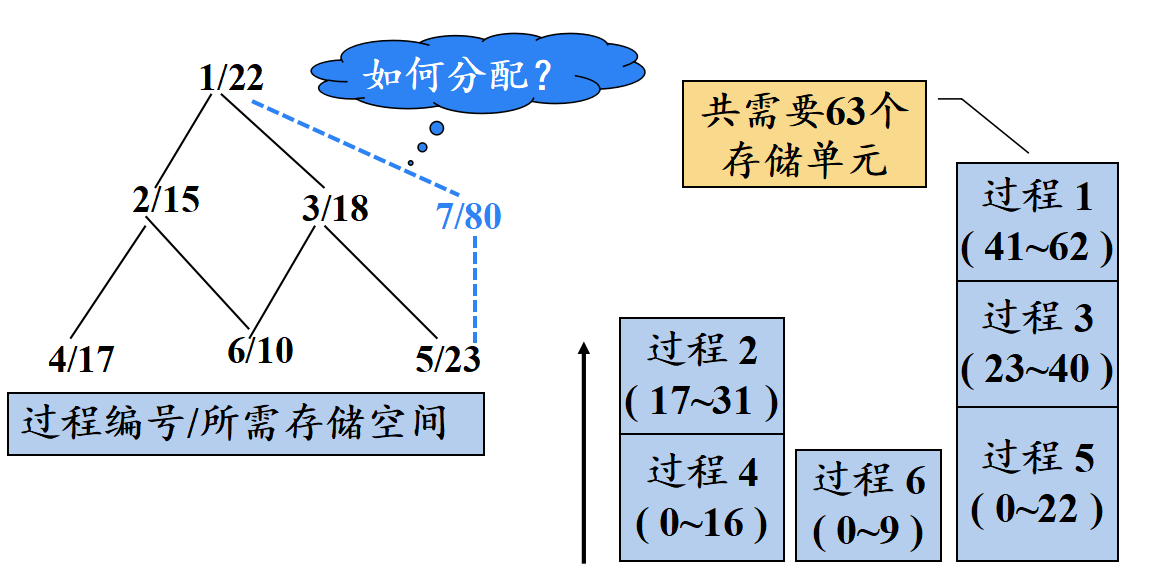
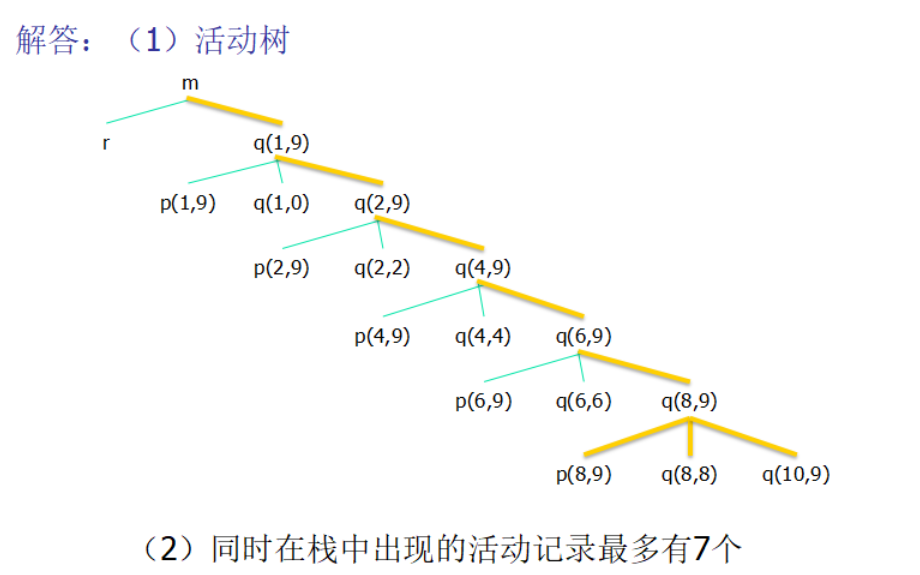
活动树
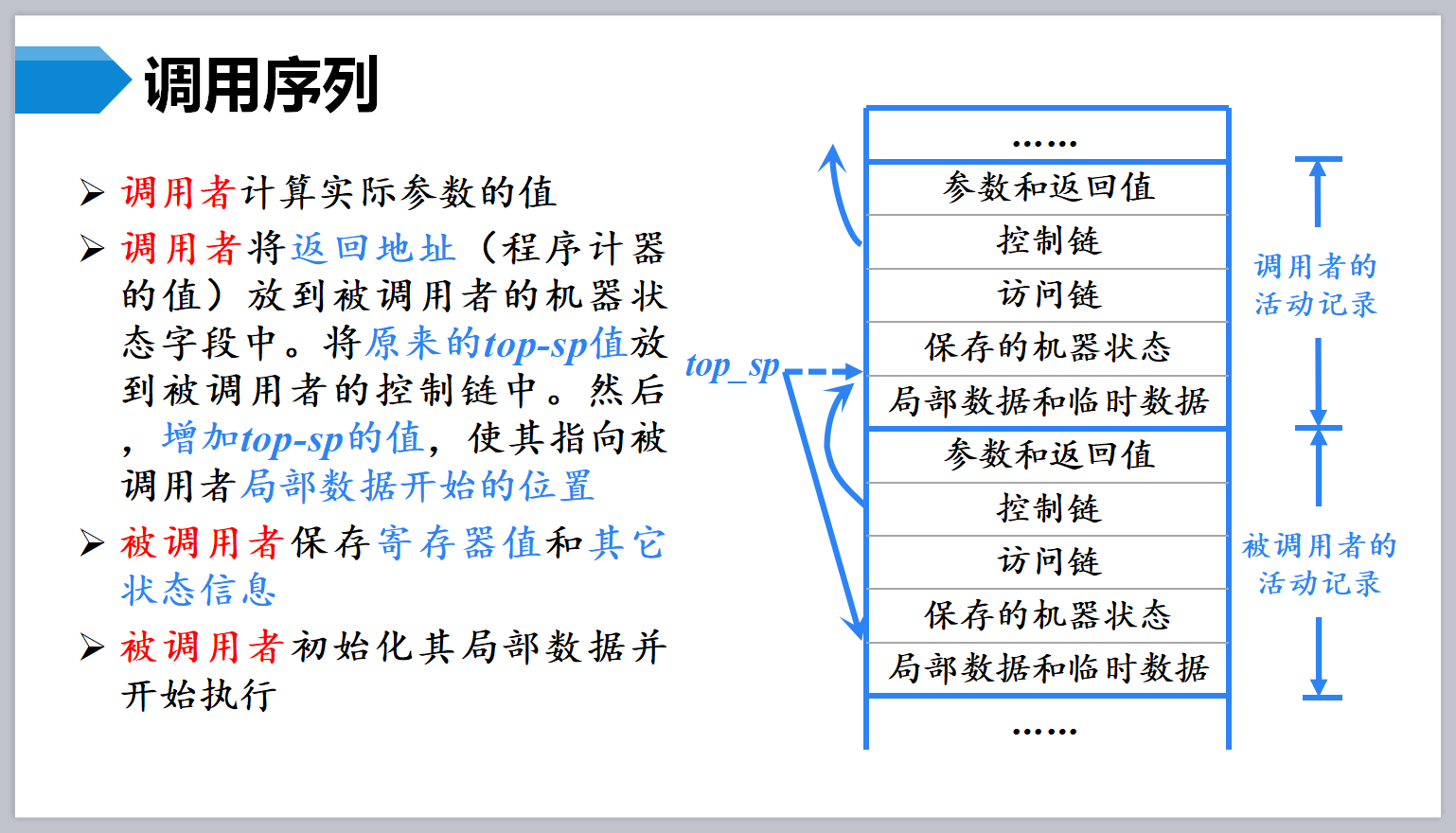
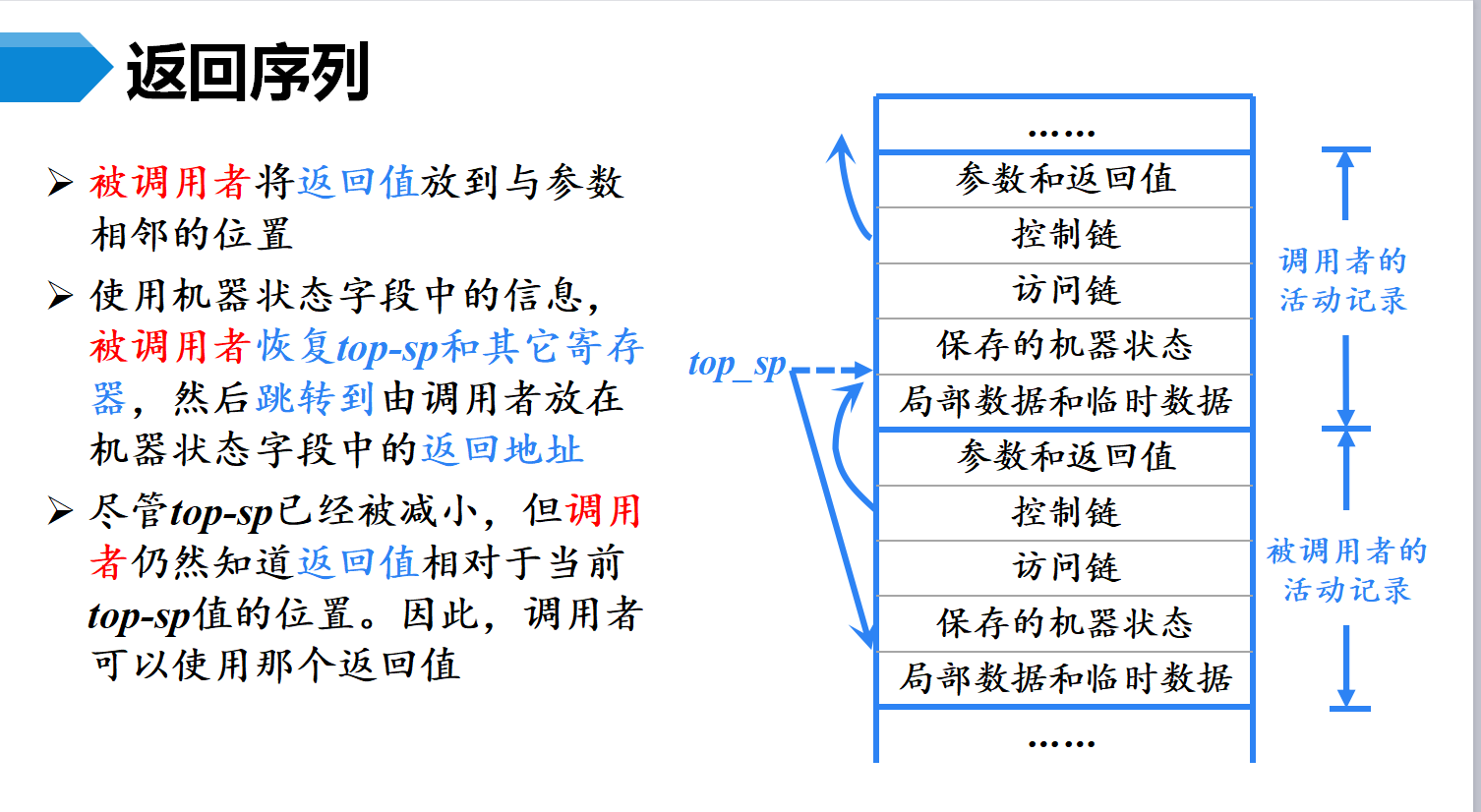
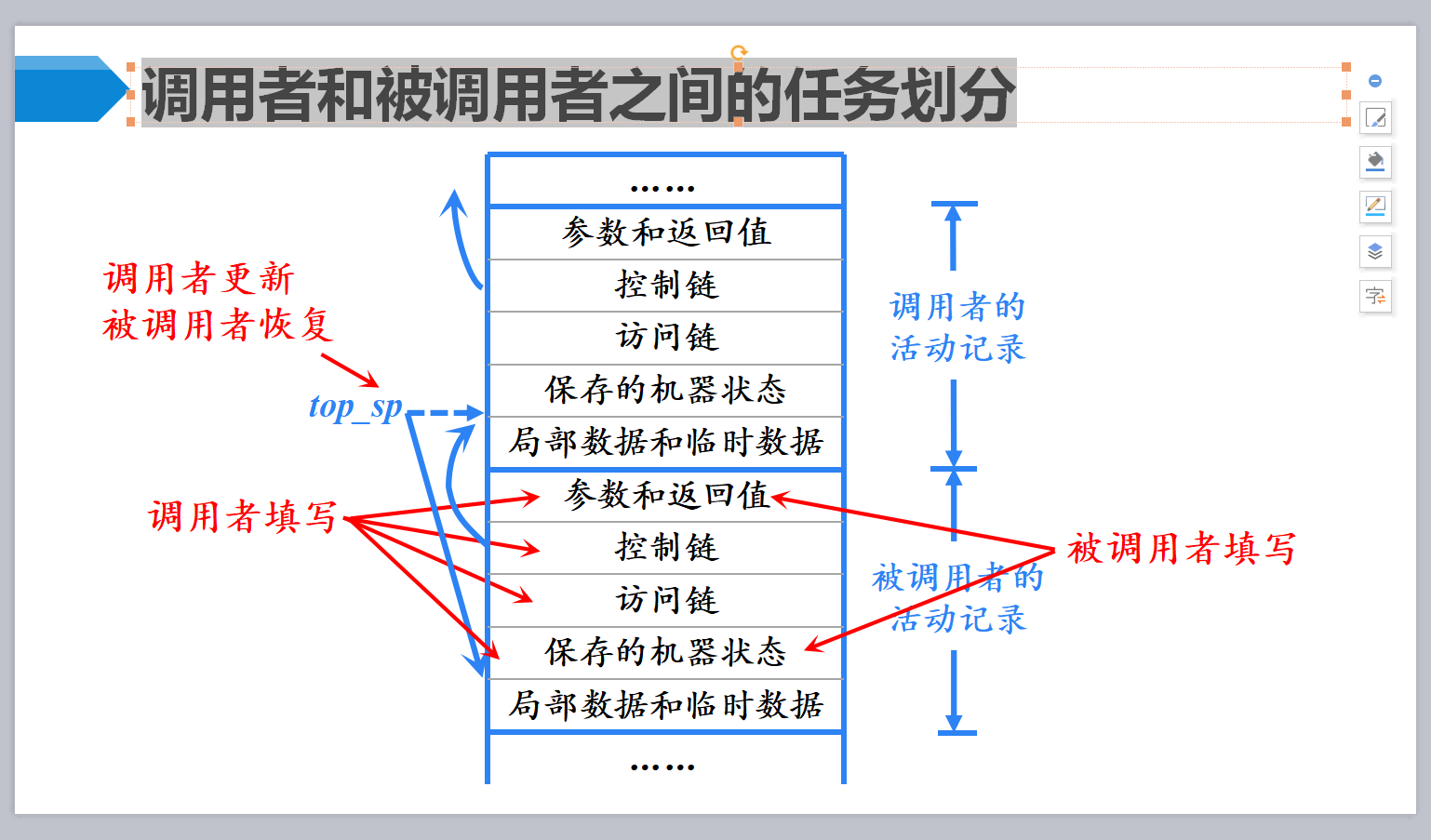
调用序列与返回序列
如果表达式x op y先前已被计算过,并且从先前的计算到现在,x op y中变量的值没有改变,那么x op y的这次出现就称为公共子表达式
复制传播:在复制语句x = y之后尽可能地用y代替x
对于一个变量x ,如果存在一个正的或负的常数c使得每次x被赋值时它的值总增加c ,那么x就称为归纳变量
数组元素赋值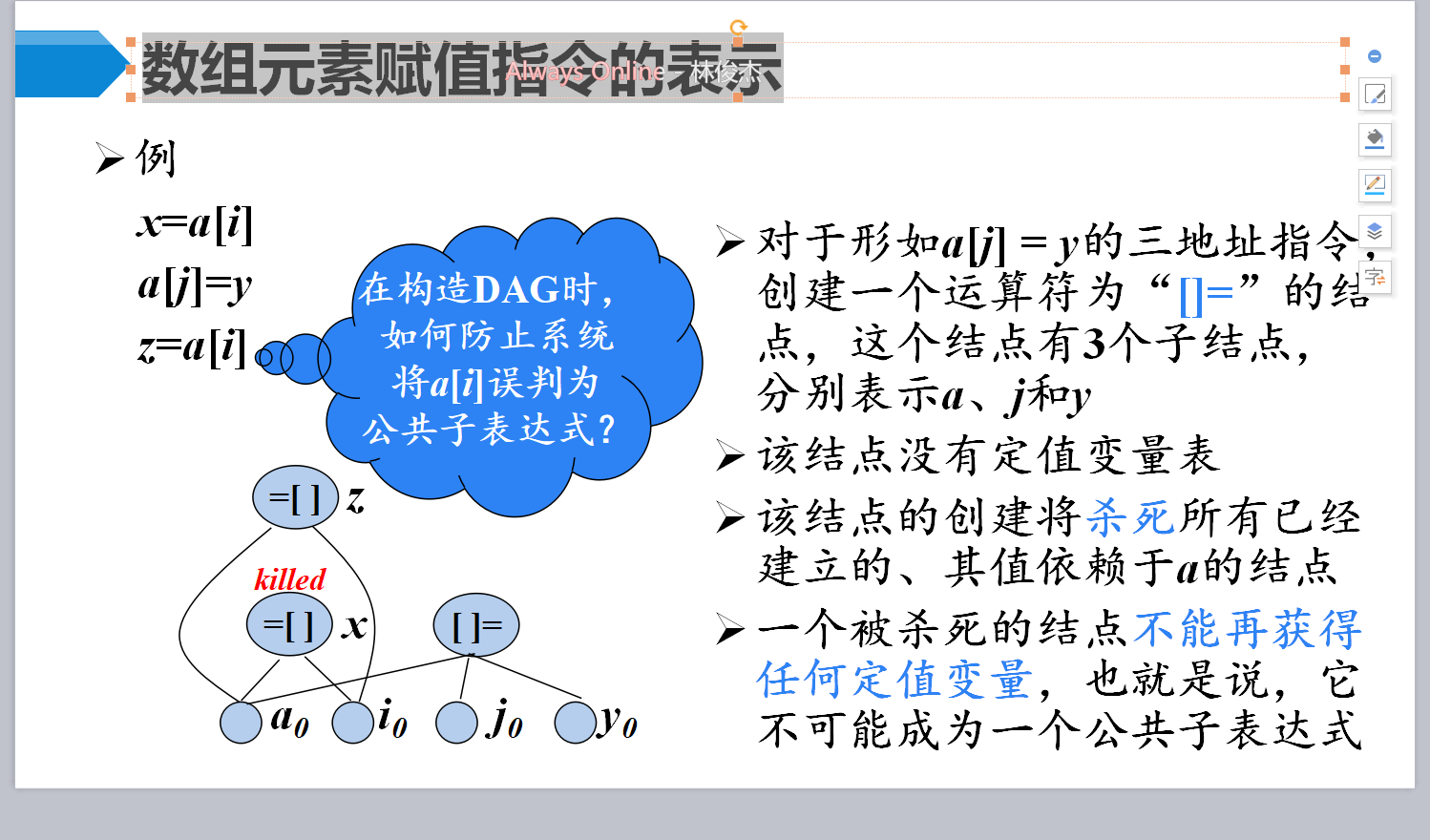
到达定值分析
正常
作用:
循环不变计算的检测
1 | 如果循环中含有赋值x=y+z ,而y和z所有可能的定值都在循环外面(包括y或z是常数的特殊情况) ,那么y+z就是循环不变计算 |
常量合并
1 | 如果对变量x的某次使用只有一个定值可以到达,并且该定值把一个常量赋给x ,那么可以简单地把x替换为该常量 |
ud链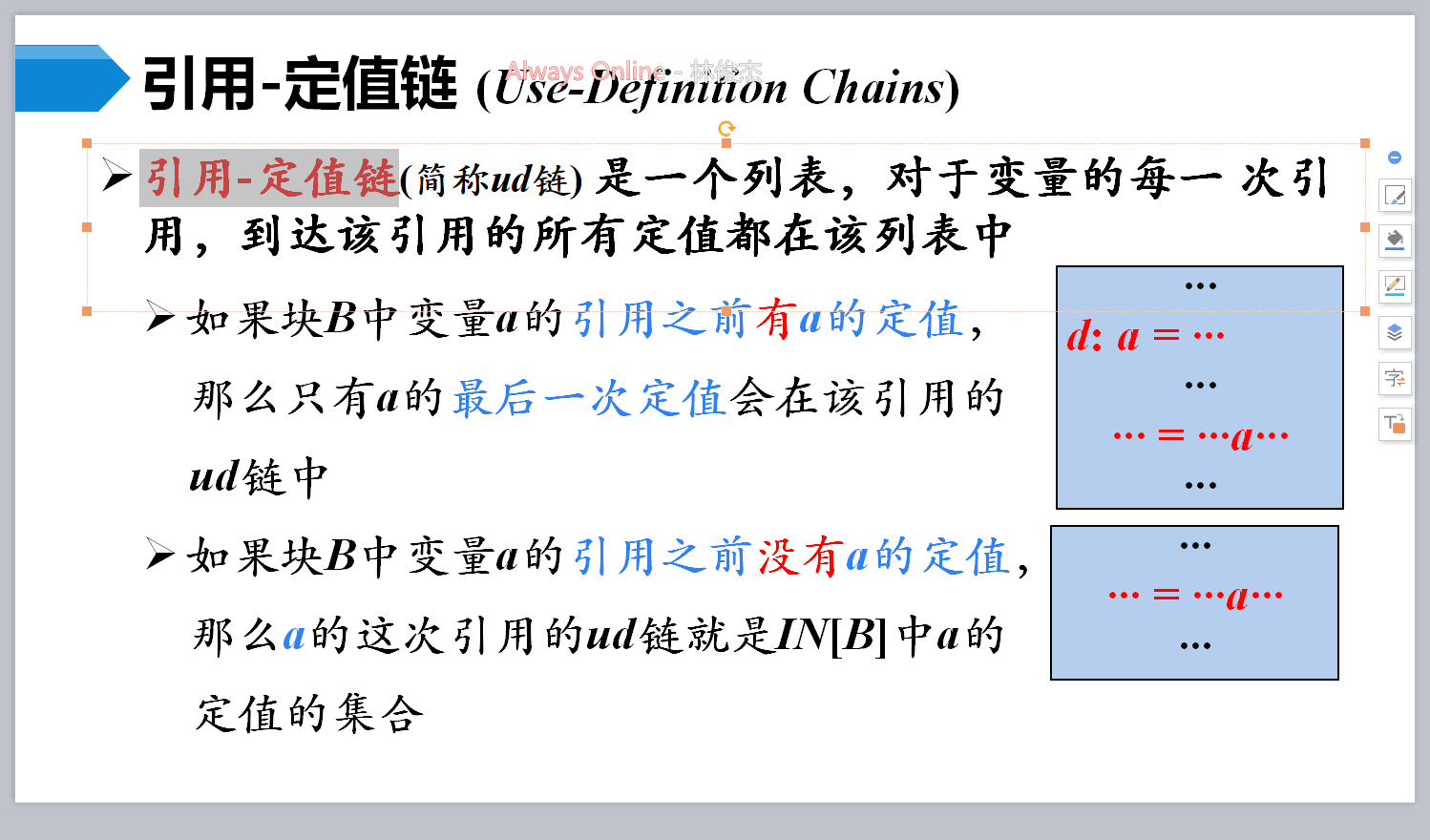
活跃变量分析
活跃变量:对于变量x和程序点p,如果在流图中沿着从p开始的某条路径会引用变量x在p点的值,则称变量x在点p是活跃(live)的,否则称变量x在点p不活跃(dead)
逆向分析
用途:
删除无用赋值
1 | 无用赋值:如果x在点p的定值在基本块内所有后继点都不被引用,且x在基本块出口之后又是不活跃的,那么x在点p的定值就是无用的 |
为基本块分配寄存器
1 | 如果所有寄存器都被占用,并且还需要申请一个寄存器,则应该考虑使用已经存放了死亡值的寄存器,因为这个值不需要保存到内存 |
du链
可用表达式分析
概念:如果从流图的首节点到达程序点 p的每条路径都对表达式x op y进行计算,并且从最后一个这样的计算到点p之间没有再次对x或y定值,那么表达式x op y在点 p是可用的
初始化时出enter外每个out都是全集
用途:
消除全局公共子表达式
进行复制传播
主要任务
1 | 指令选择 |
词素分析
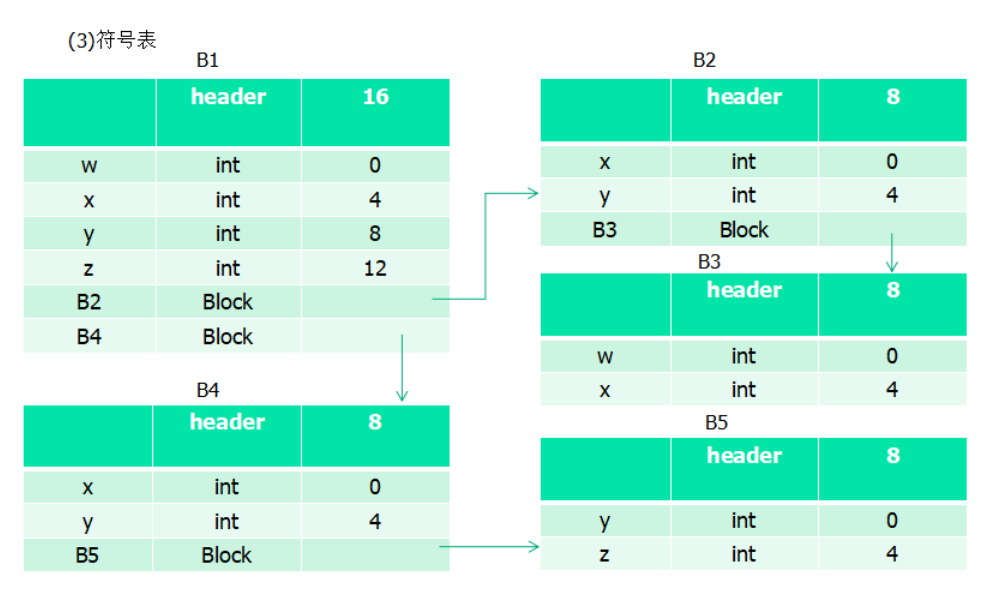
符号表
递归的预测分析

非递归的预测分析
设计SDD


改写SDT


递归的翻译


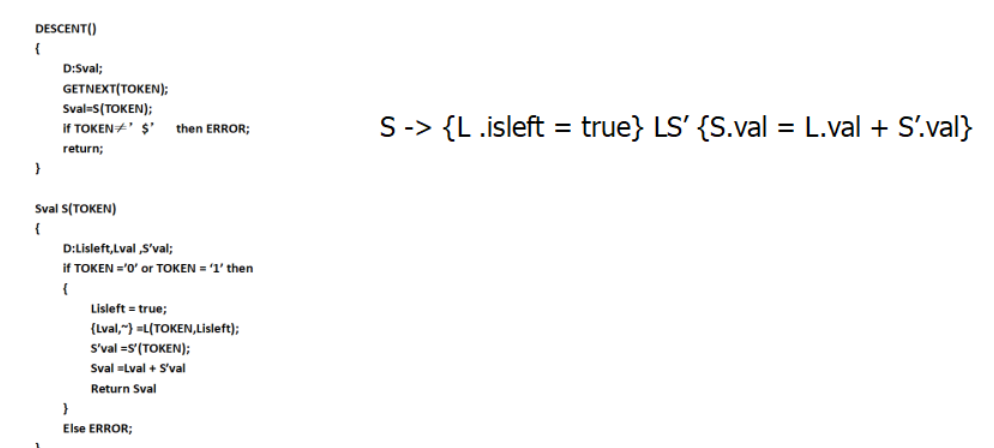
非递归的翻译
活动记录
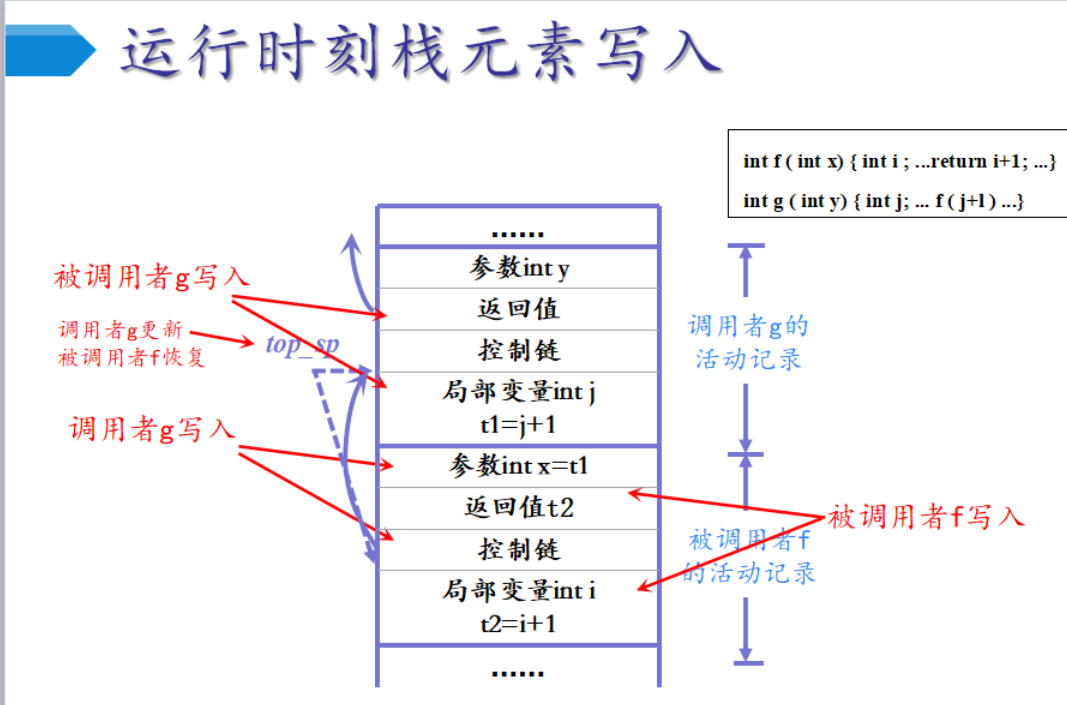
嵌套深度
找自然循坏
全局优化
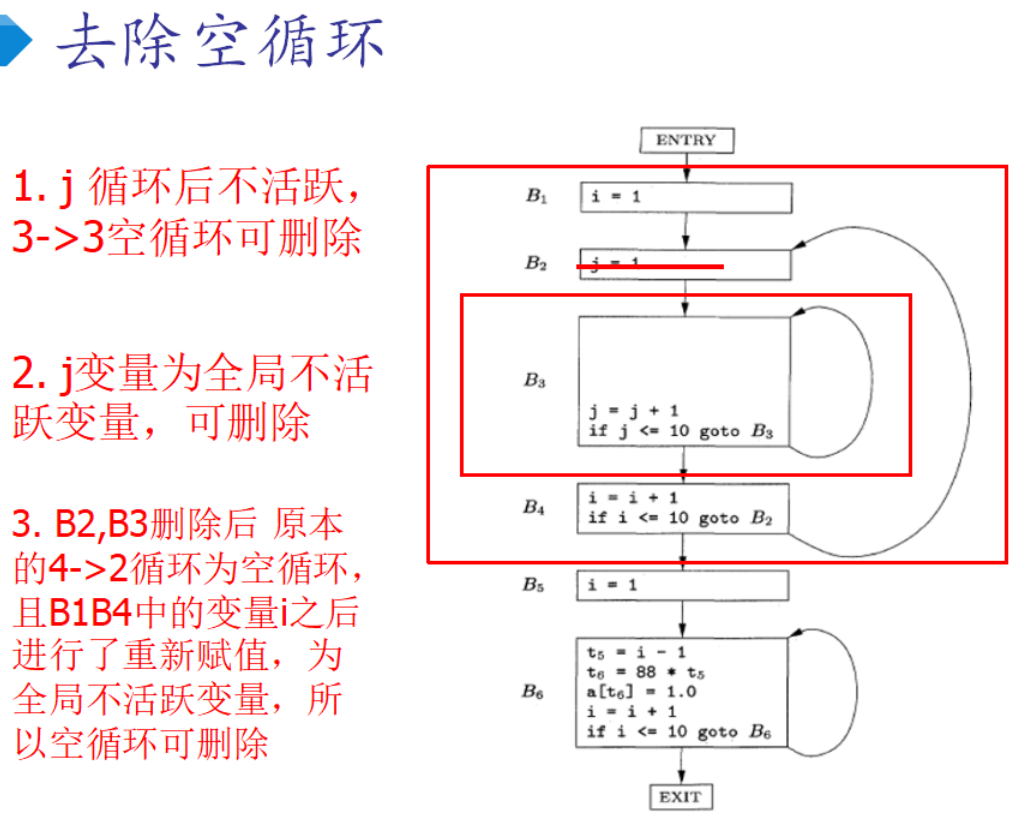
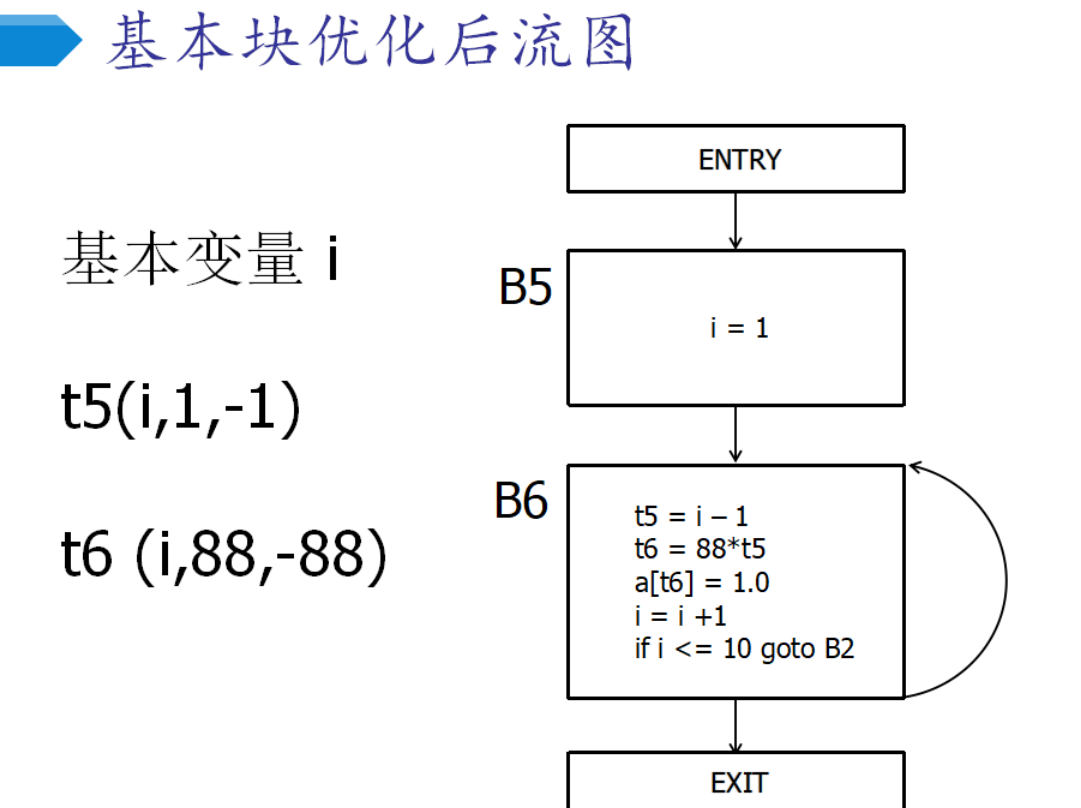
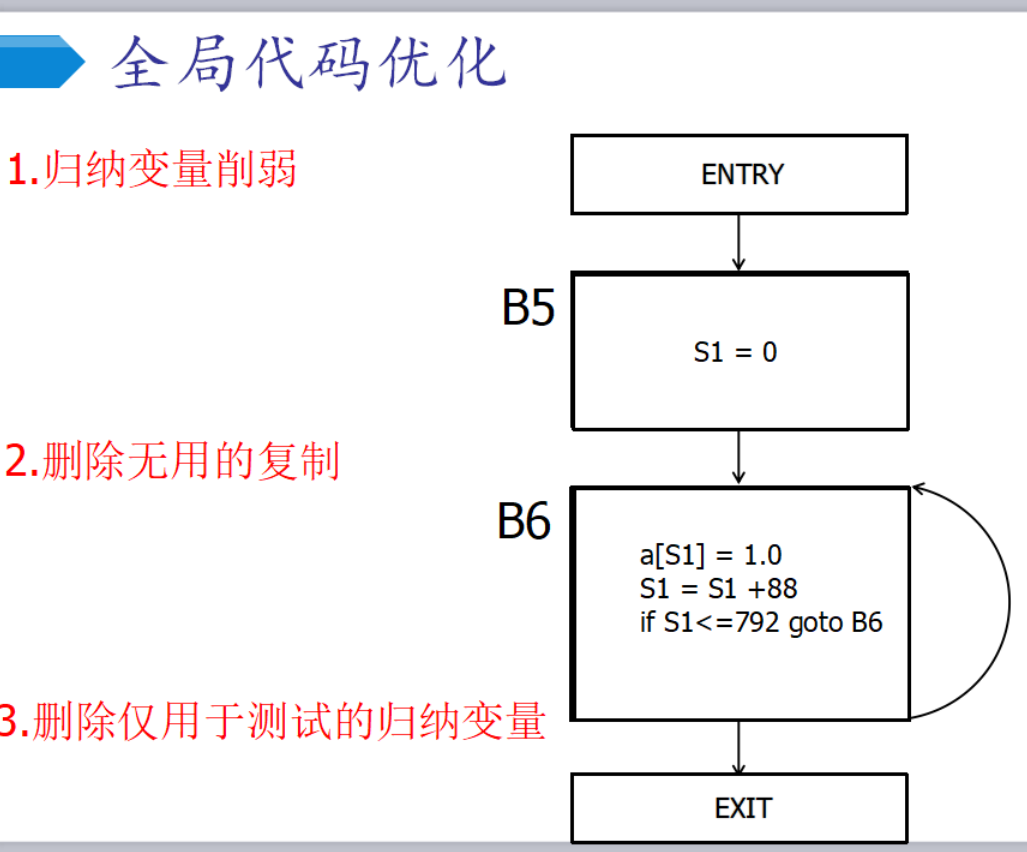
句柄
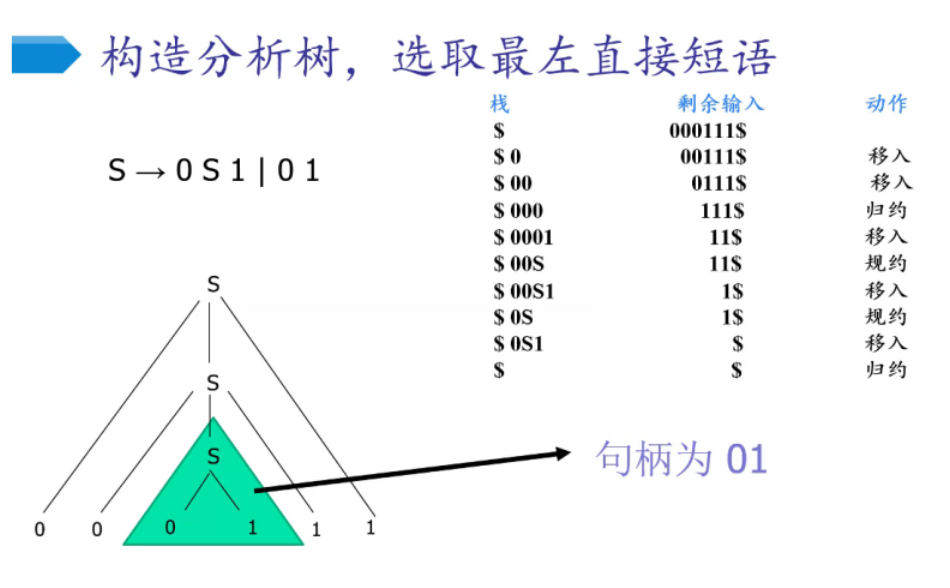
注释语法分析树

翻译赋值语句

控制流翻译
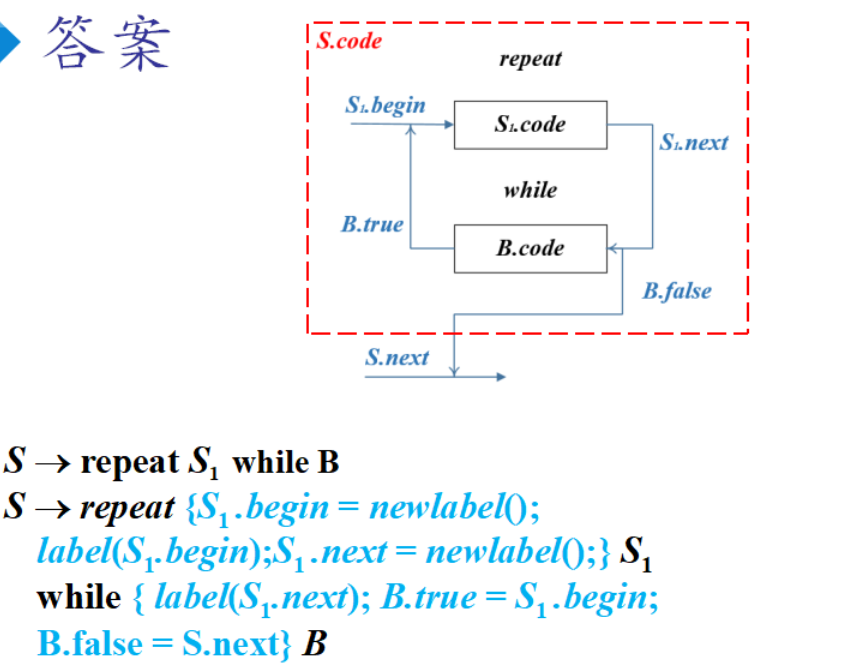
四元式序列

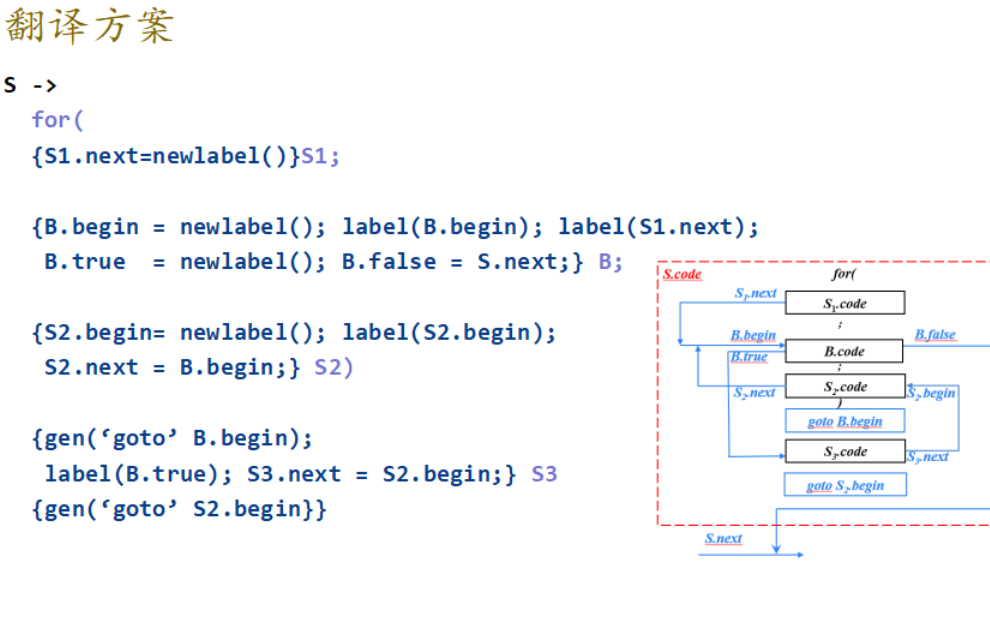
翻译方案
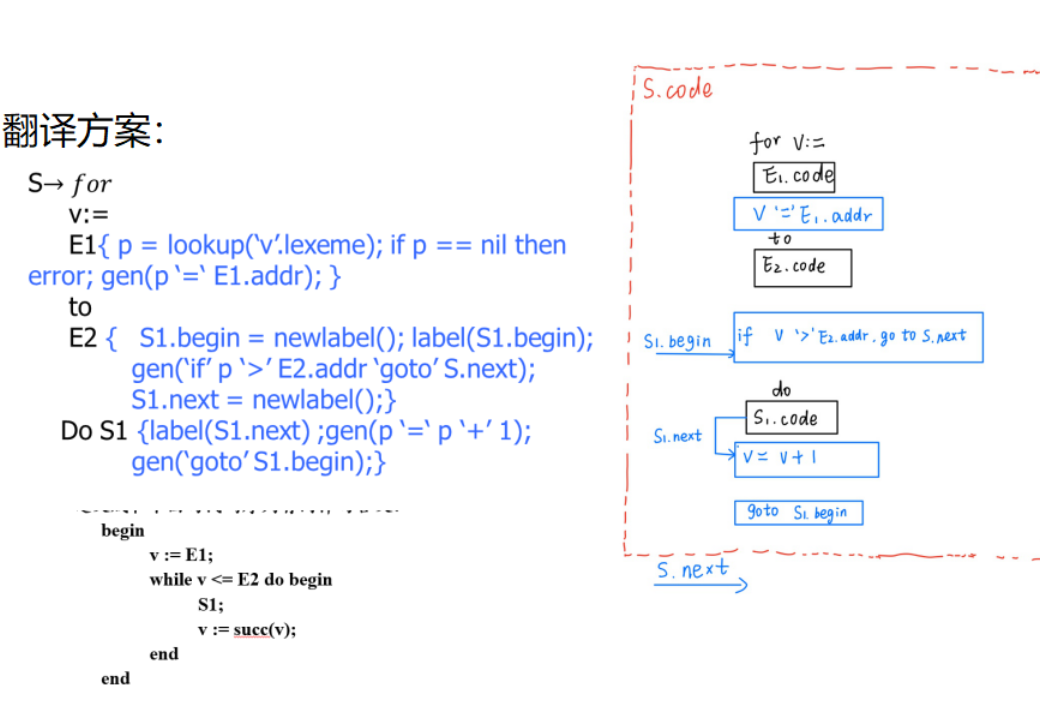
13.5 难
13.6
14.4
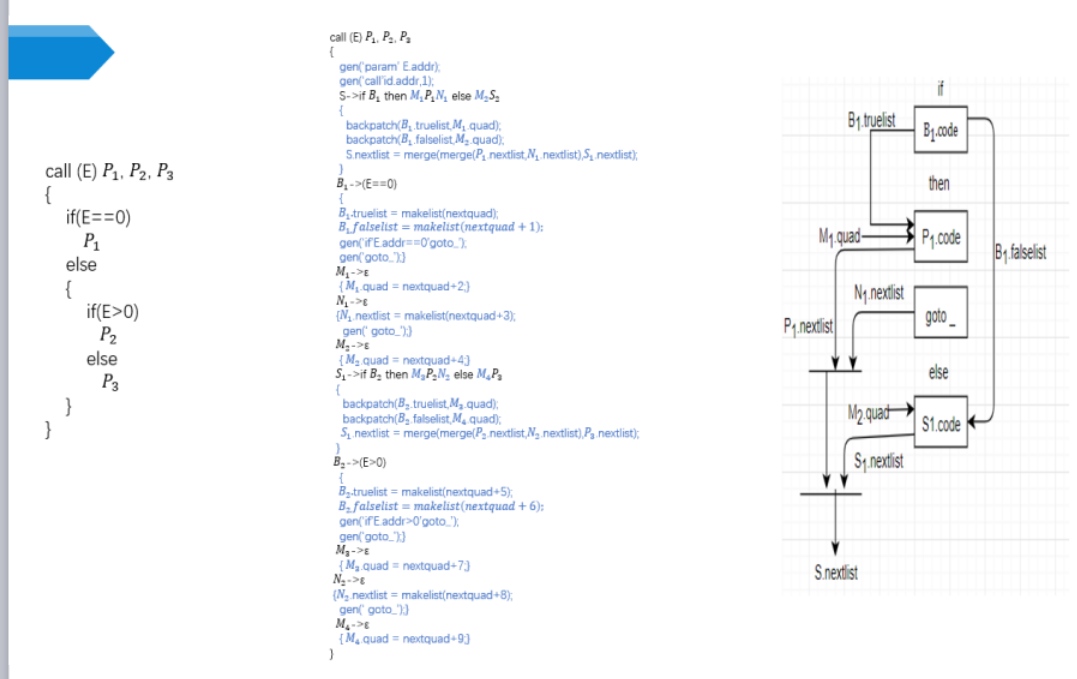
求trulist
活动树
DAG

数值分析